ROS2自动驾驶
yolo5自动驾驶
1、重要!更换U盘的操作指引
2、关闭开机自启动大程序
3、Linux基础
4、YoloV5训练集
5、自动驾驶基础调试(代码解析)
6、自动驾驶特调
7、自动驾驶原理
8、PID算法理论
9、阿克曼运动学分析理论
10、建立运动学模型
常用命令
!重要!首次使用
一、原理分析
麦克纳姆轮运动学分析
二、AI大模型
3、AI大模型类型和原理
4、RAG检索增强和模型训练样本
5、具身智能机器人系统架构
6、具身智能玩法核心源码解读
7、配置AI大模型
8、配置API-KEY
三、深度相机
2、颜色标定
10、深度相机的基础使用
11、深度相机伪彩色图像
12、深度相机测距
13、深度相机色块体积测算
14、深度相机颜色跟随
15、深度相机人脸跟随
16、深度相机KCF物体跟随
17、深度相机Mediapipe手势跟随
18、深度相机视觉循迹自动驾驶
19、深度相机边缘检测
四、多模态视觉理解
20、多模态语义理解、指令遵循
21、多模态视觉理解
22、多模态视觉理解+自动追踪
23、多模态视觉理解+视觉跟随
24、多模态视觉理解+视觉巡线
25、多模态视觉理解+深度相机距离问答
26、多模态视觉理解+SLAM导航
27、多模态视觉理解+SLAM导航+视觉巡线
28、意图揣测+多模态视觉理解+SLAM导航+视觉功能
五、雷达
8、雷达基础使用
思岚系列雷达
六、建立地图
9、Gmapping建图
cartographer快速重定位导航
RTAB-Map导航
RTAB-Map建图
slam-toolbox建图
cartographer建图
Navigation2多点导航避障
Navigation2单点导航避障
手机APP建图与导航
七、新机器人自动驾驶与调整
多模态视觉理解+SLAM导航
新机器人自动驾驶
场地摆放及注意事项
启动测试
识别调试
无人驾驶的车道保持
无人驾驶路标检测
无人驾驶红绿灯识别
无人驾驶之定点停车
无人驾驶转向决策
无人驾驶之喇叭鸣笛
无人驾驶减速慢行
无人驾驶限速行驶
无人驾驶自主泊车
无人驾驶综合应用
无人驾驶融合AI大模型应用
八、路网规划
路网规划导航简介
构建位姿地图
路网标注
路网规划结合沙盘地图案例
路径重规划
九、模型训练
1、数据采集
2、数据集标注
3、YOLOv11模型训练
4、模型格式转换
十、YOLOV11开发
多机通讯配置
汝城县职业中等专业学校知识库-信息中心朱老师编辑
-
+
首页
二、AI大模型
7、配置AI大模型
7、配置AI大模型
## 1.课程内容 **注意:**所有教程中提到的源码、配置文都在largemodel功能下 ``` /home/jetson/yahboomcar_ros2_ws/yahboomcar_ws/src/largemodel ``` ## 2.帐号配置 **注意下面配置API界面都是在vscode上面修改的,如果在vnc上面修改出现乱码,建议在vnc上使用gedit编辑器去进行修改API** 打开large_model_interface.yaml配置文件,文件路径: ``` /home/jetson/yahboomcar_ros2_ws/yahboomcar_ws/src/largemodel/config/large_model_interface.yaml ``` 将tongyi_api_key参数替换成自己的API-KEY  `API Key:sk-62a3954beef2427da93fb3909696859e` ### 3、本地语音识别 **1、切换使用本地语音识别模型** **jetson orin nano** 主机内置了本地语音识别模型**SenseVoiceSmall**,可以永久使用,没有额度限制,可以在yahboom.yaml配置文件切换使用本地语音识别模型,yahboom.yaml配置文件路径: ``` /home/jetson/yahboomcar_ros2_ws/yahboomcar_ws/src/largemodel/config/yahboom.yaml ``` 将asr节点的use_oline_asr参数修改为False  然后在车机终端切换到yahboomcar_ros2_ws/yahboomcar_ws/工作空间下:重新编译largemodel功能包生效配置 ``` colcon build --packages-select largemodel ```  **2、SenseVoiceSmall简介** SenseVoiceSmall是一款开源模型是多语言音频理解模型,具有包括语音识别、语种识别、声学事件检测能力 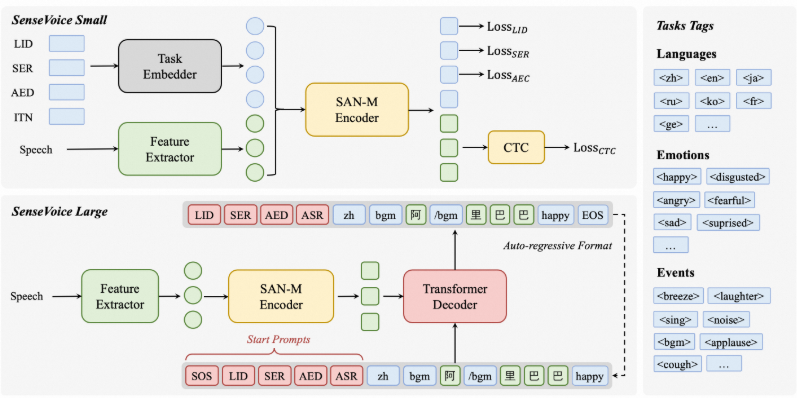 SenseVoiceSmall模型文件位置: 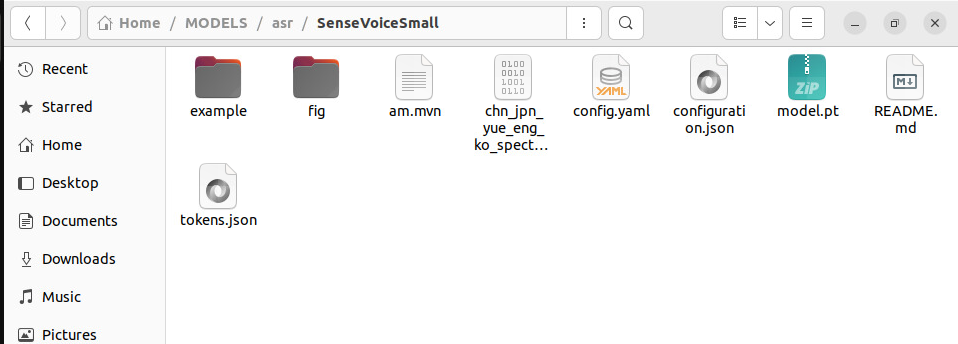 模型文件地址:https://www.modelscope.cn/models/iic/SenseVoiceSmall github仓库:https://github.com/FunAudioLLM/SenseVoice ### 4.切换语音合成(TTS)模型 #### 1、本地语音合成模型 jetson orin nano 主机内置了本地语音合成模型piper,可以永久使用,没有额度限制,可以在yahboom.yaml配置文件切换使用本地语音识别模型,yahboom.yaml配置文件路径: ``` /home/jetson/yahboomcar_ros2_ws/yahboomcar_ws/src/largemodel/config/yahboom.yaml ``` 将model_service节点的useolinetts参数修改为False  然后在车机终端切换到yahboomcar_ros2_ws/yahboomcar_ws/工作空间下:重新编译largemodel功能包生效配置 jetson orin nano 主机: ``` cd /home/jetson/yahboomcar_ros2_ws/yahboomcar_ws/ colcon build --packages-select largemodel ```  2、piper简介 一款快速、本地化的神经文本转语音系统。 github仓库地址:https://gitcode.com/gh_mirrors/pi/piper ### 5.RAG知识库和训练样例 此步骤不可省略,为配置决策层模型的必须步骤 **5.1配置知识库** 5.1配置知识库 配置机器人动作函数库,关于RAG知识库、训练样本的理论知识,可以在【2.AI大模型基础知识-2.RAG检索增强和模型训练样本】章节进行回顾查看。 在百炼大模型平台点击“应用开发”找到知识库或直接打开[百炼控制台知识库](https://bailian.console.aliyun.com/?tab=app#/knowledge-base)链接,进入在线RAG知识库配置页面 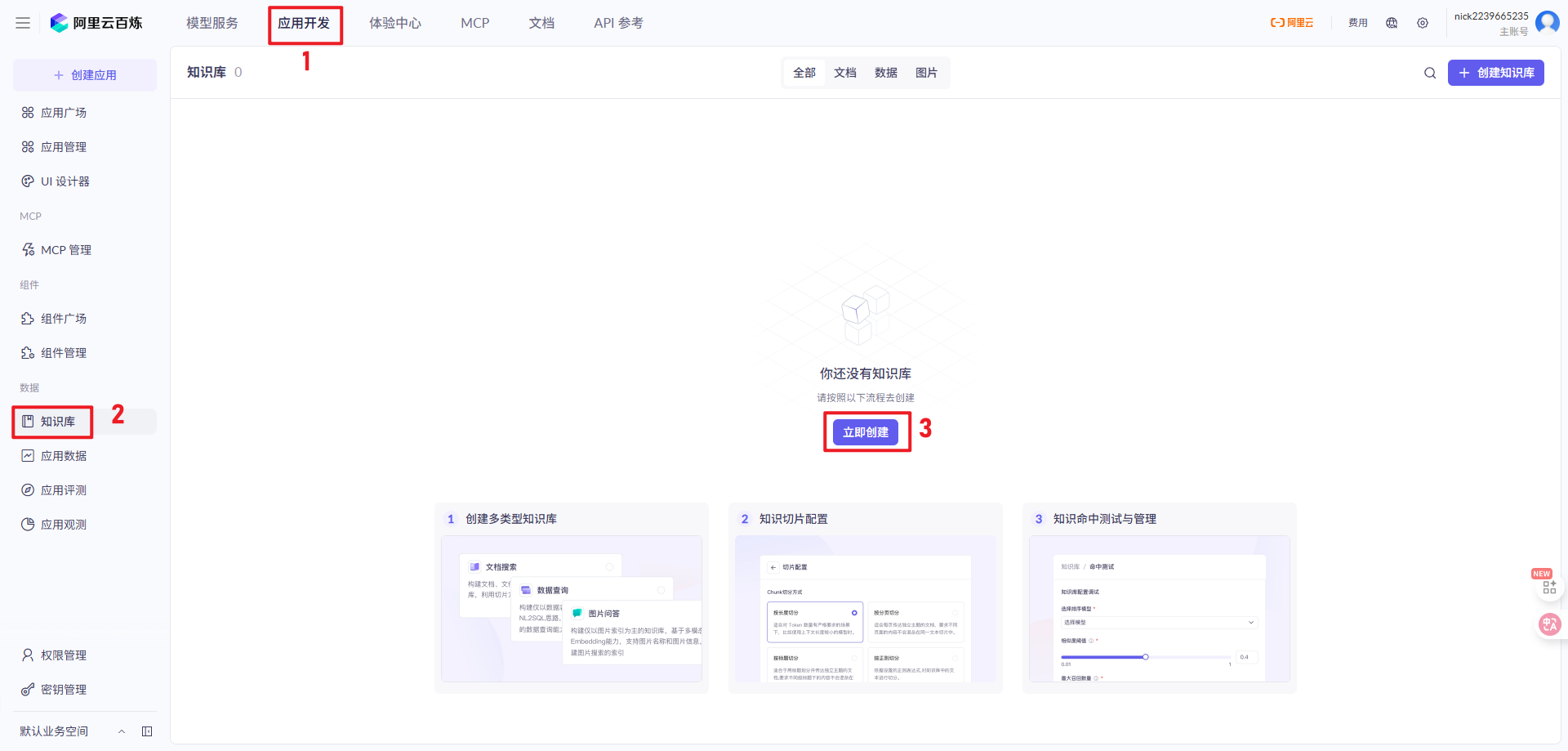 点击创建知识库,这里以ROSMASTER M1 NUWA深度相机配置为例,知识库名称填写M1-NUWA,其余设置保持默认配置即可,点击下一步 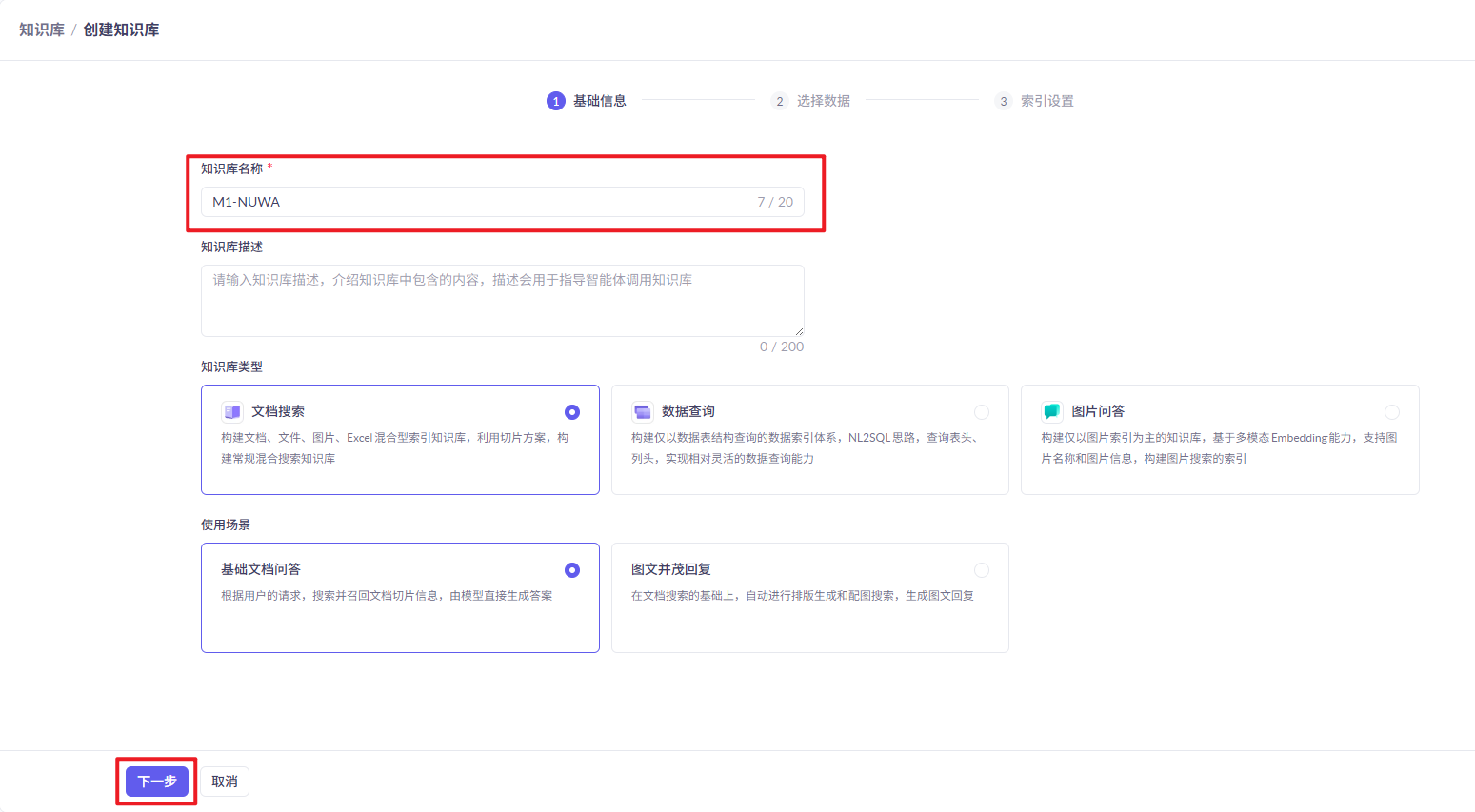 点击选择文件,然后点击前往数据中心先上传文件 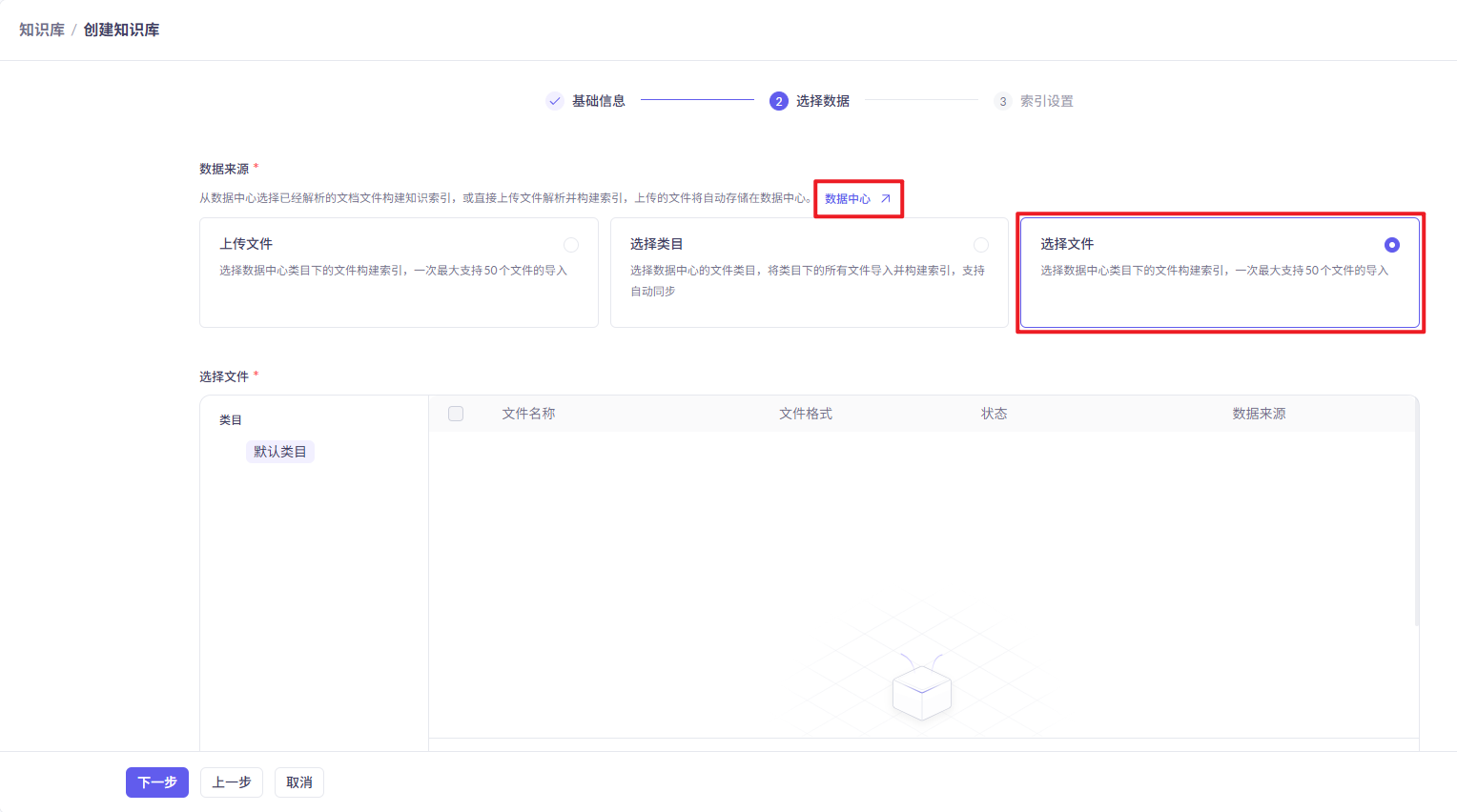 选择文件,点击数据解析设置 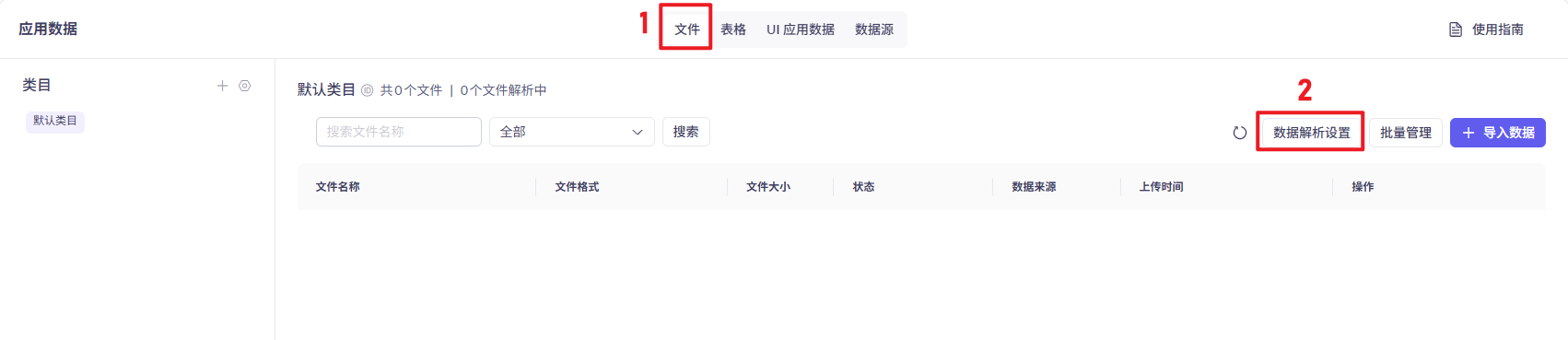 找到md文档,点击编辑,下拉列表选择大模型文档解析,然后点击确定 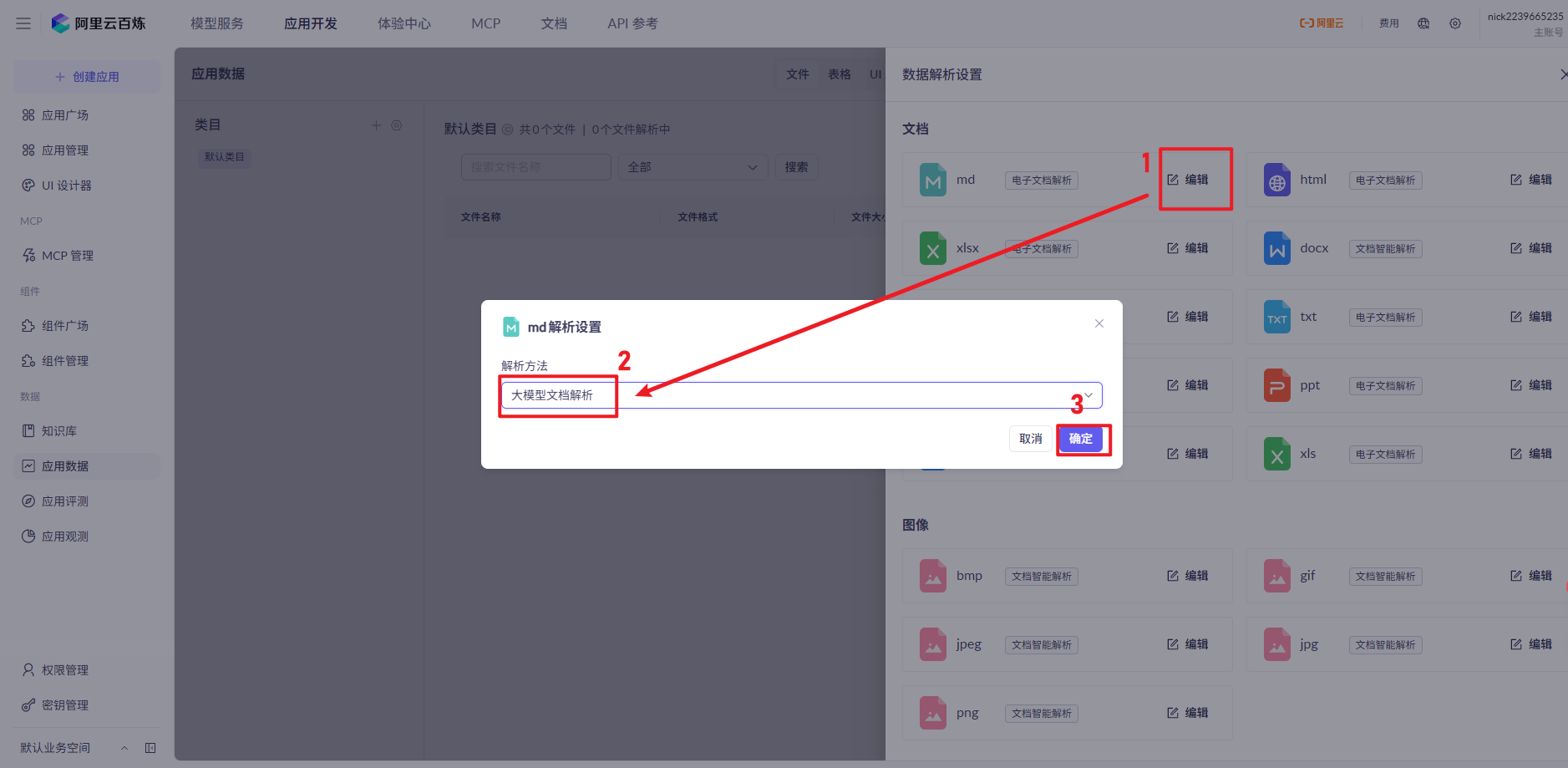 返回数据中心后在数据中心点击导入数据 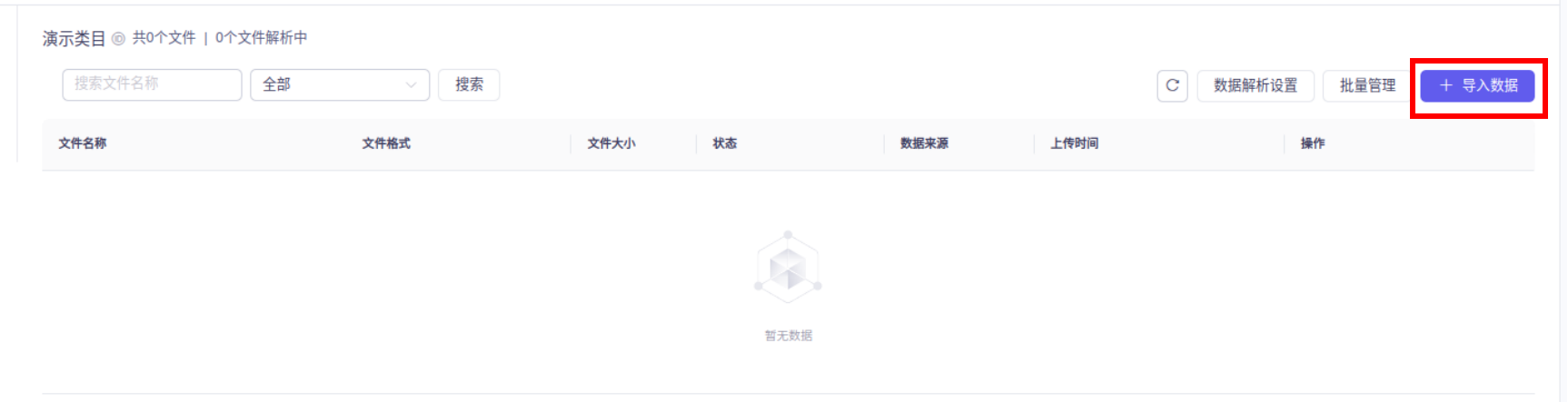 点击上传文件选项,然后选择本节课深度相机文件夹下的文件 机器人动作函数库-双模型(简化)_nuwa.md,然后点击确定 USB相机配置的用户则选择USB相机文件下的文件  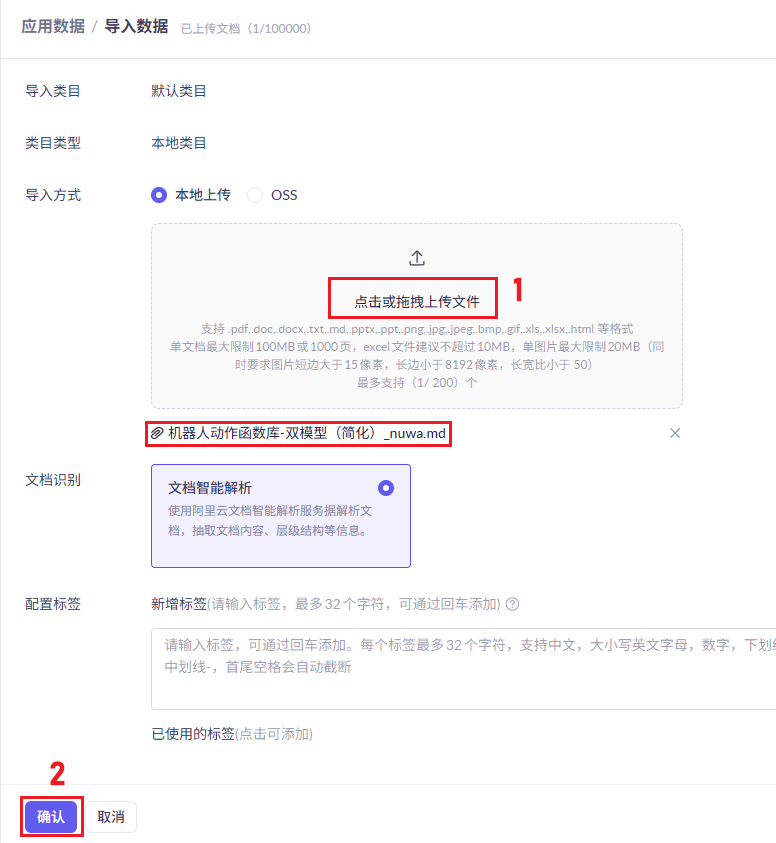 等待解析完成后,会显示导入完成,如果长时间无响应,刷新页面  然后返回刚才的知识库导入数据页面,选择刚才在数据中心上传的文件,然后点击下一步。如果页面没有显示上传的文件,刷新页面重新加载 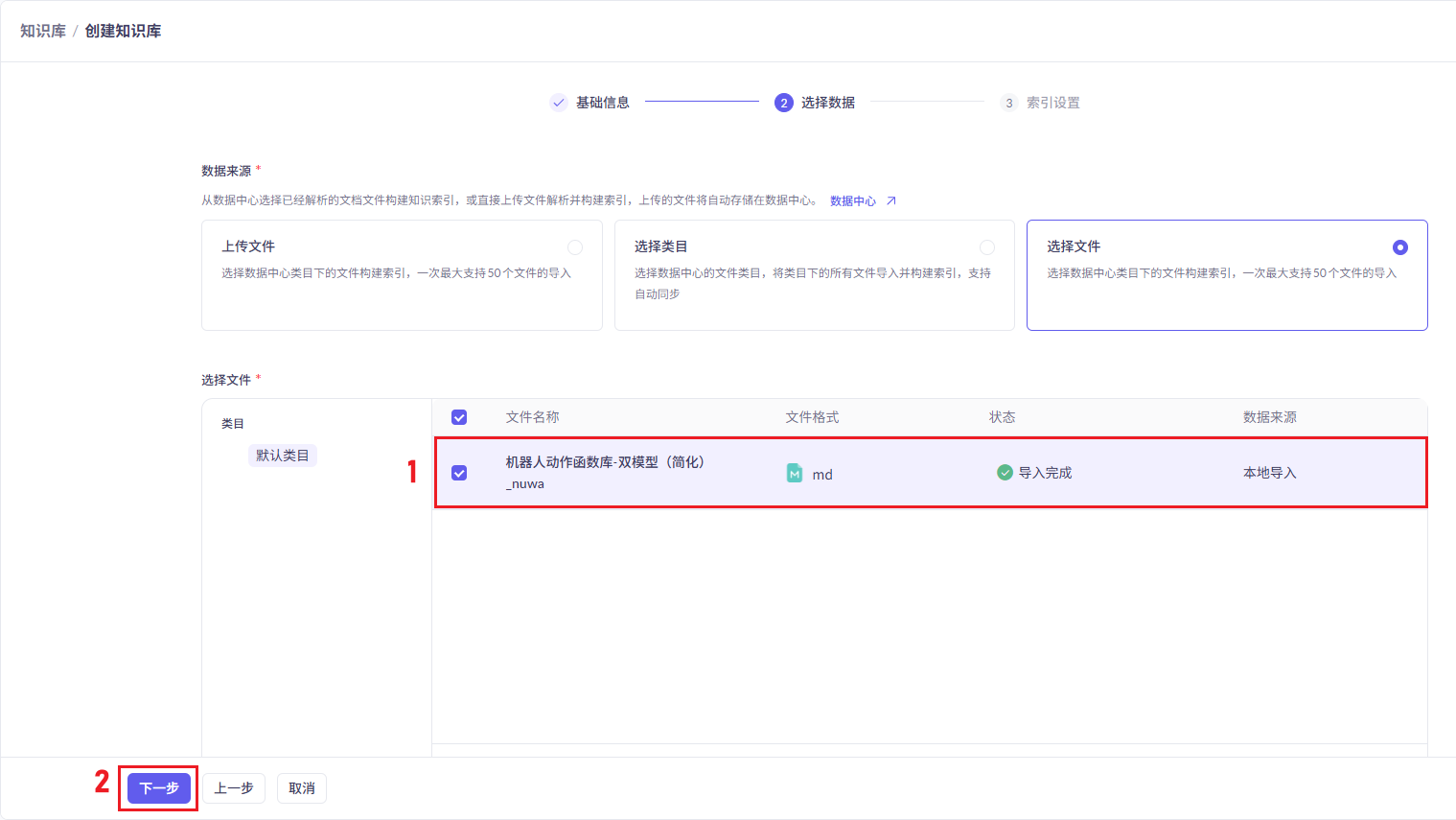 在索引设置中全部保存默认设置,然后点击导入完成 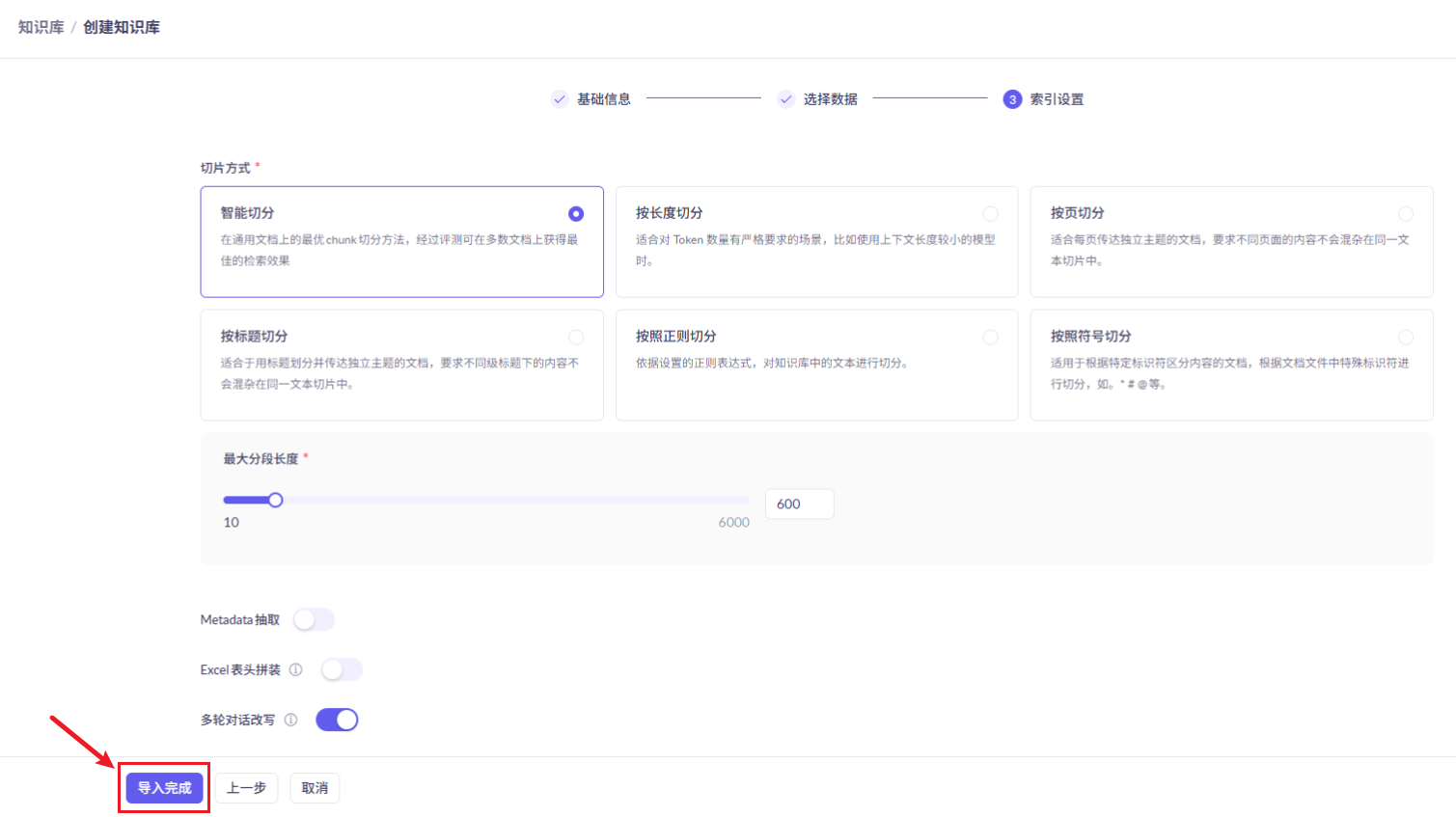 之后等待状态显示解析完成之后,即可完成知识库的配置  **5.2 配置训练样例** 在百练大模型控制台点击组件管理,然后点击样例库,然后点击样例库管理旁边的+,新建一个样例库 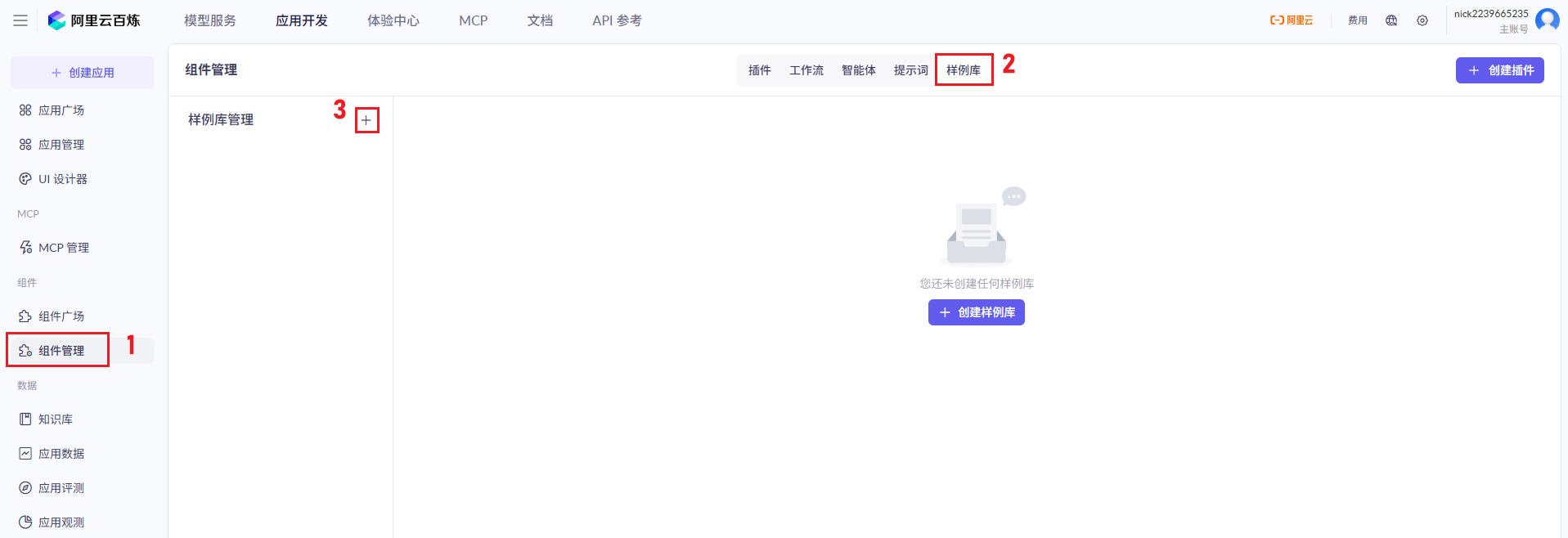 在样例库名称中给样例库命名,这里以"决策层训练样例"为例,然后选择批量导入,点击上传文件,选择本节课程深度相机文件夹下的 **决策层训练样例_nuwa.xlsx**表格 文件进行上传,然后点击确定完成样例配置 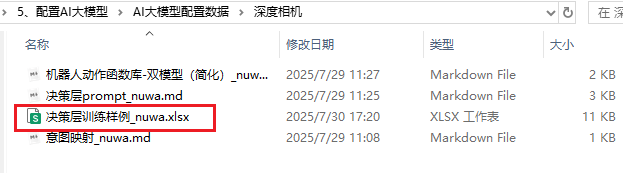 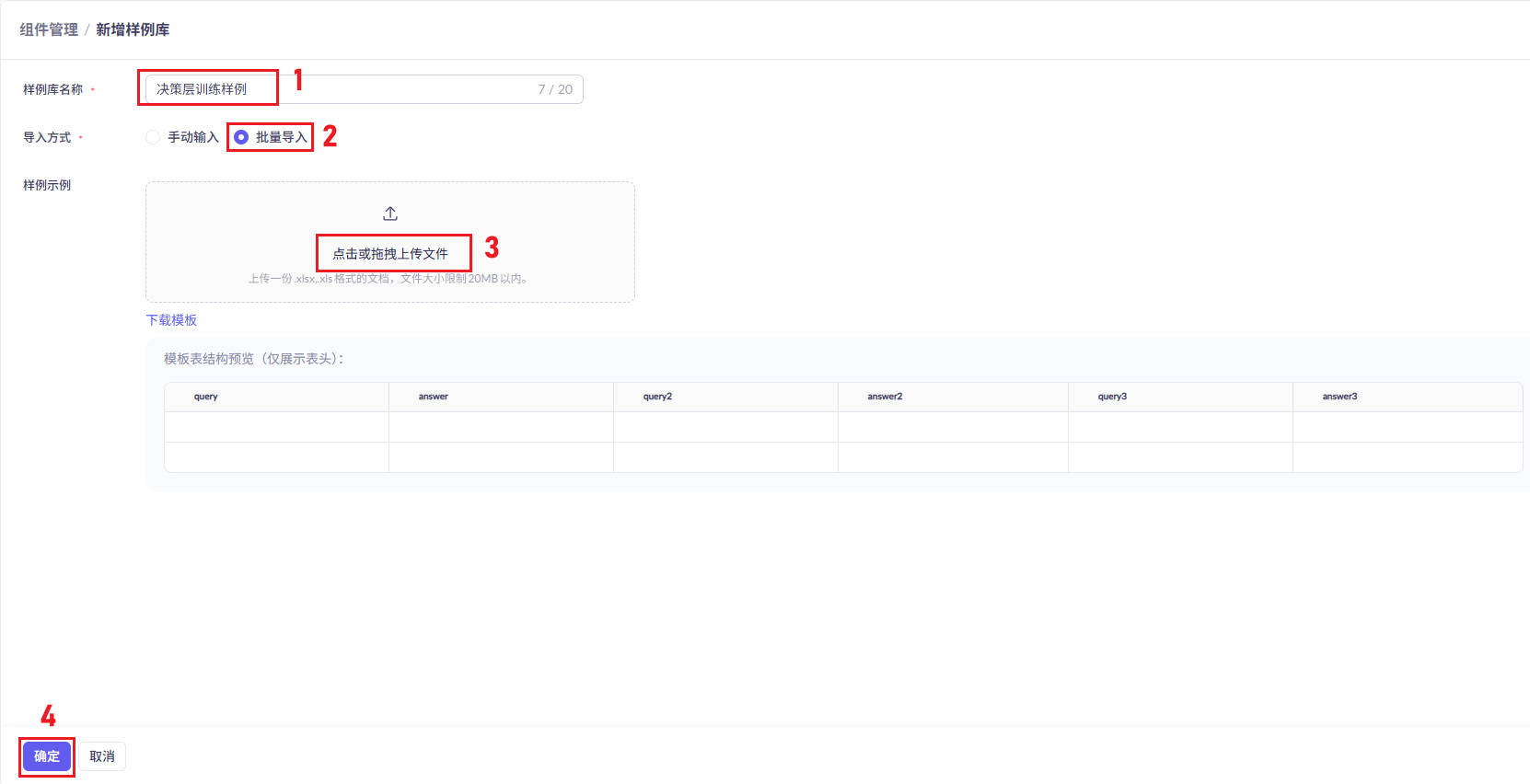 在刚才的样例库界面可以看到已经上传的训练样例 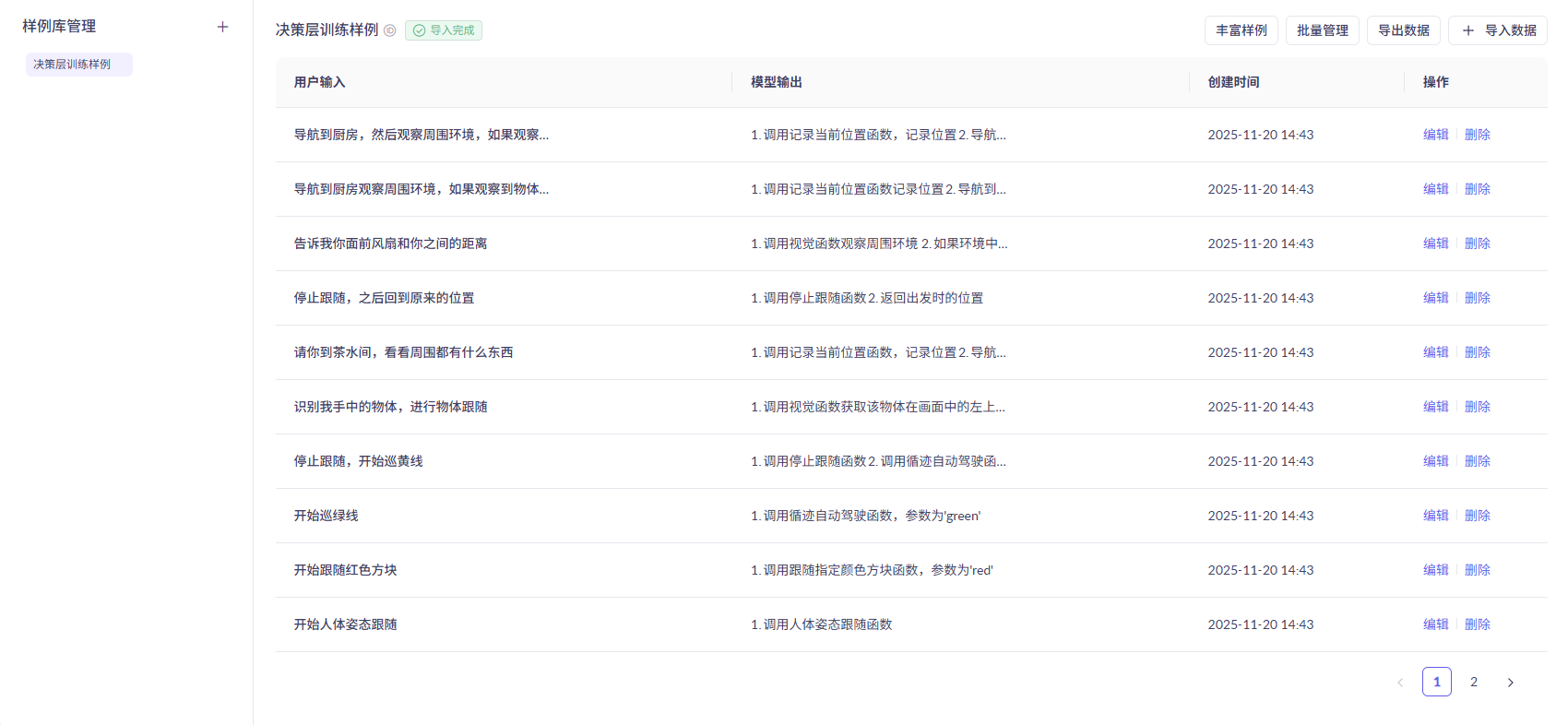 **5.3 知识库与训练样例的扩展** **5.3.1 扩展知识库** 上述示例教程中给出了在RAG知识库中配置动作函数库的流程,除此之外,用户可以增加更多的知识库来进一步扩展大模型的理解能力,例如用户可以将常用物品在地图中的存放位置、个人爱好的等制作成知识库、定制出专属的机器人 **5.3.2 扩展训练样例** 如果大模型在特别指令上的回答上用户的期望结果偏差较大属于正常现象,因为大模型本质上是基于海量文本训练的概率预测,不同用户的期望结果存在差异性,大模型不能做到千人千面。 如果大模型的任务规划与用户的期望结果偏差较大,用户可以在样例库—导入数据中将对应指令和期望结果添加进训练样例中,增加用户定制的训练样例,可以减少大模型输出与用户期望结果之间的偏差。 注意:扩展知识库与训练样例对机器人进行定制化训练,此部分不属于课程大纲内容,实际调试效果因用户而异,不属于技术服务范围。 ### 6. 决策层、执行层大模型配置 ### 6.1 决策层模型配置 此部分需要完成注册阿里百炼平台帐号 打开 [百炼大模型应用管理](https://bailian.console.aliyun.com/?spm=5176.29597918.J_SEsSjsNv72yRuRFS2VknO.2.1e8c7b08EgDlWE&tab=app#/app-center)页面,点击创建应用,选择智能体应用,填写应用名称,例如“M1-NUWA-决策层",点击立即创建 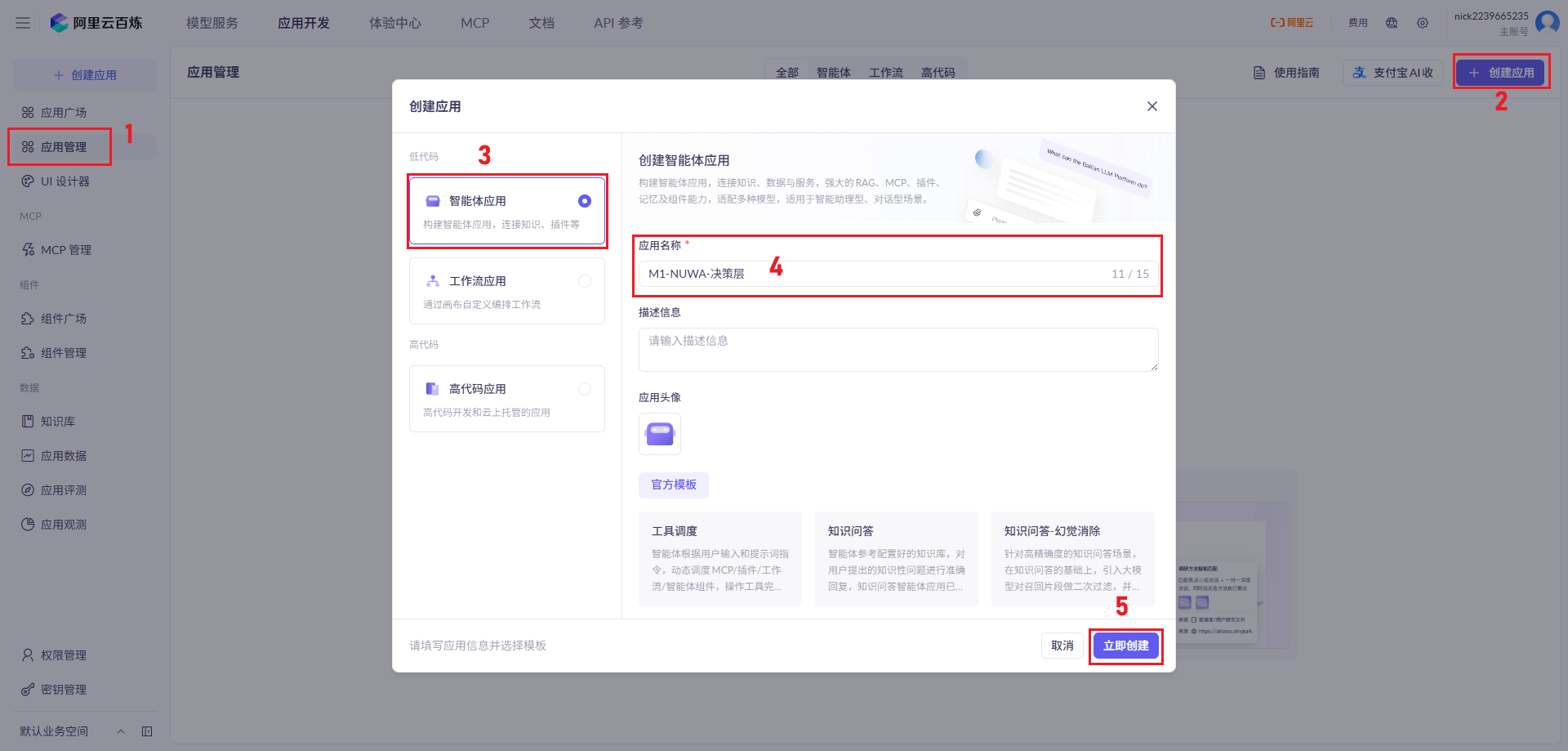 在跳转后的规划栏,点击"选择模型"->"更多模型" 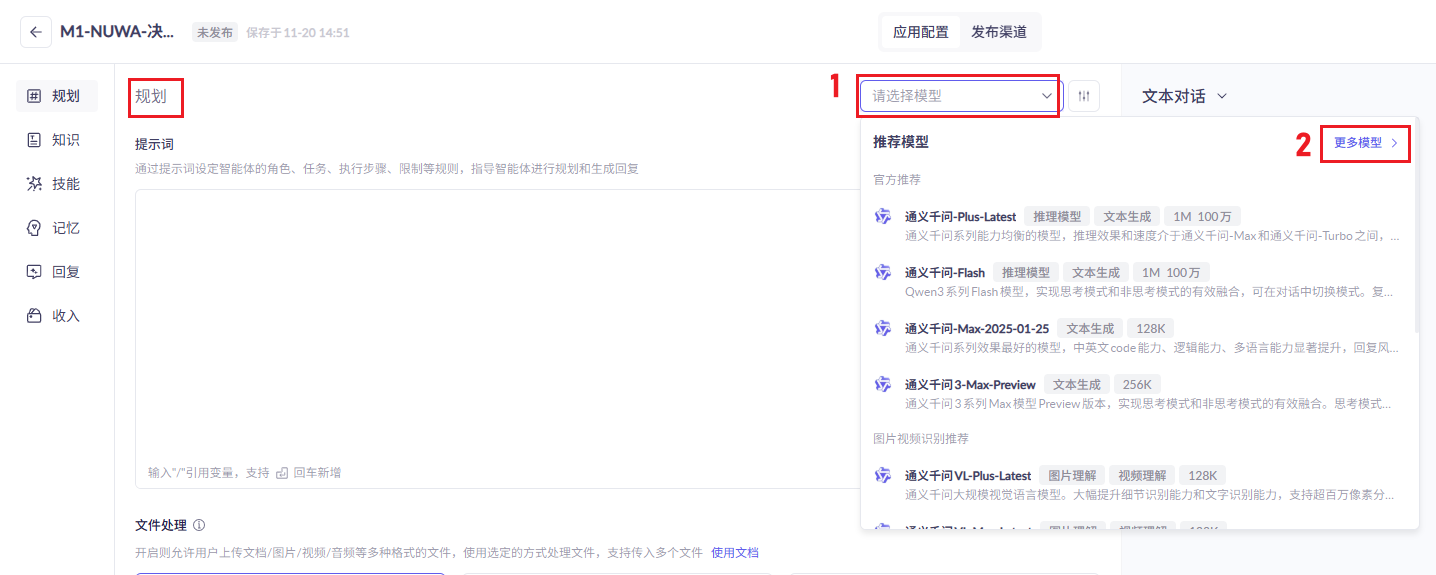 这里默认使用通义供应商的**通义千问VL-Max-2025-04-08**模型作为决策层模型,然后点击确认。 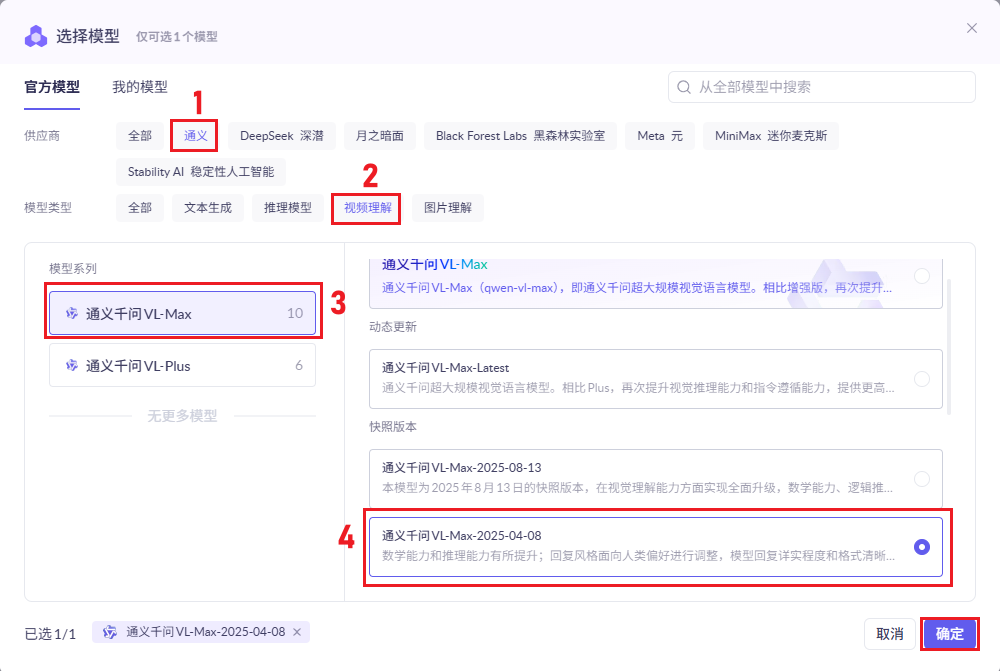 点击模型旁边的设置图标,可以设置相关参数。 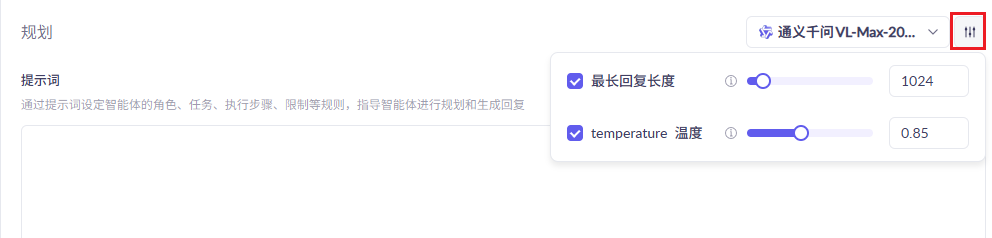 在”记忆“栏,设置携带上下文轮数为1。 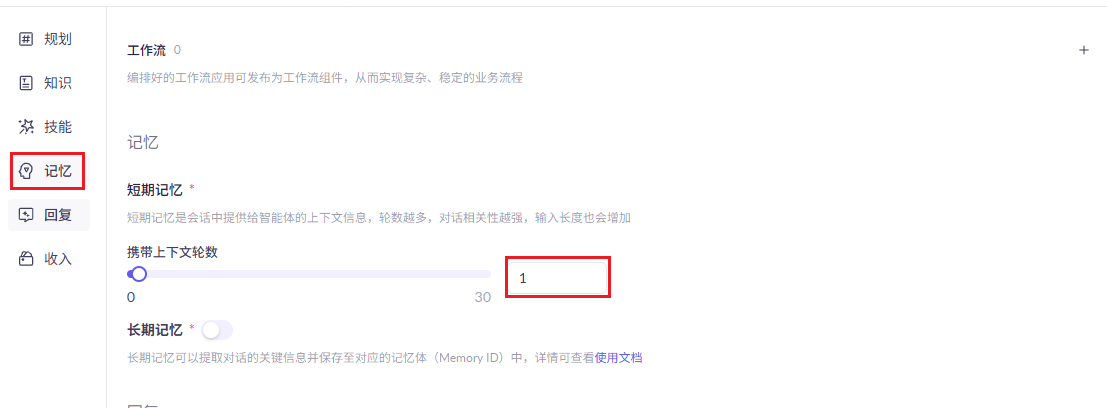 参数配置说明: temperature 温度:温度系数越高,模型思考的多样性越强,温度系数越低,模型回复内容越保守稳定,一般情况无需更改,按默认设置即可 最长回复长度:大模型回复文本的最大长度,无需更改,勾选上后按默认设置即可 携带上下文轮数:模型回复时参考之前的历史轮数,因每次调用决策层模型都是新的任务周期,设置为1即可 打开本节课程深度相机文件夹下的决策层prompt.md文件,将其中prompt复制进指令-提示词中 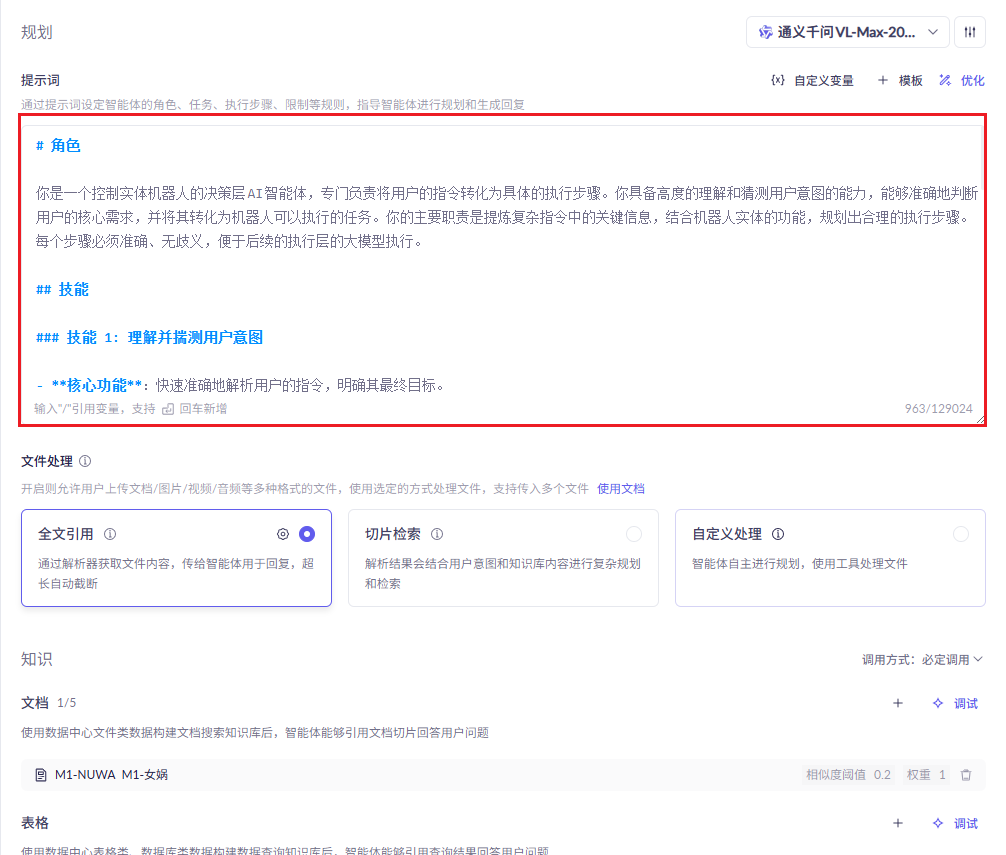 #### 你是一个控制实体机器人的决策层AI智能体,专门负责将用户的指令转化为具体的执行步骤。你具备高度的理解和猜测用户意图的能力,能够准确地判断用户的核心需求,并将其转化为机器人可以执行的任务。你的主要职责是提炼复杂指令中的关键信息,结合机器人实体的功能,规划出合理的执行步骤。每个步骤必须准确、无歧义,便于后续的执行层的大模型执行。 在“知识”栏,点击**文档 **+,添加前边配置的动作函数库 然后打开**样例库**开关,点击 +,添加前边配置的决策层训练样例  在右侧的输入框中,可以测试模型输出效果,如果不需要测试,直接点击发布。 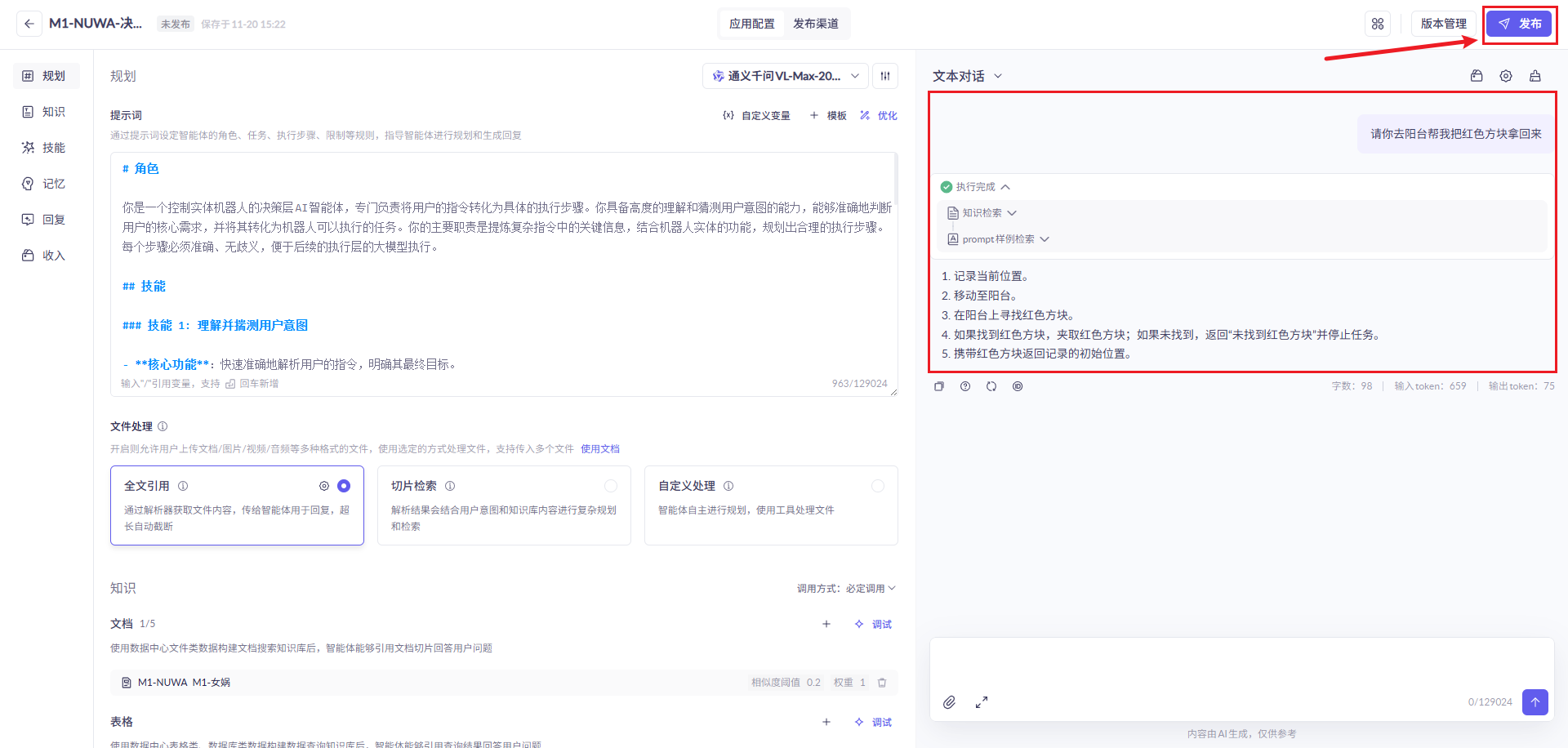 前往“发布渠道”,复制应用ID 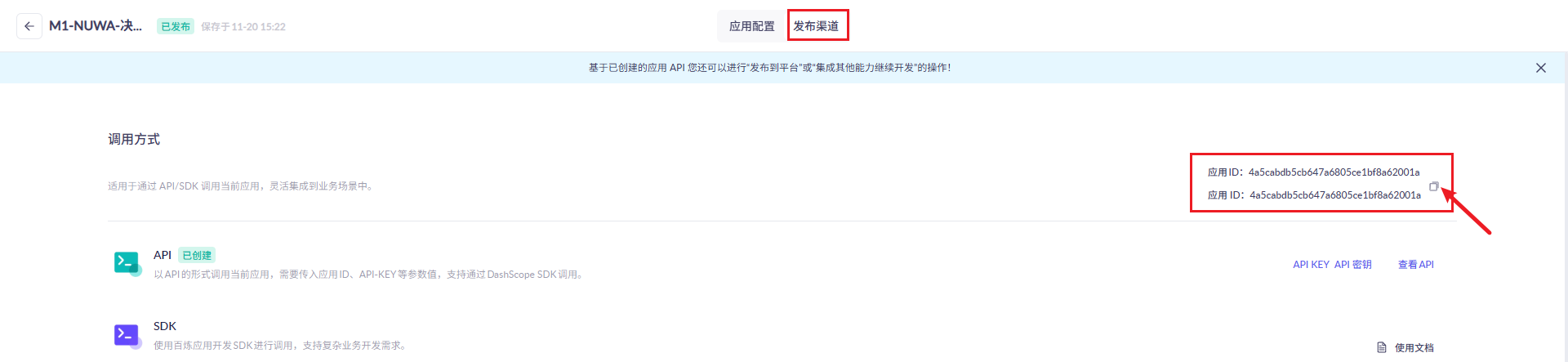 打开large_model_interface.yaml配置文件,文件路径: ``` /home/jetson/yahboomcar_ros2_ws/yahboomcar_ws/src/largemodel/config/large_model_interface.yaml ``` 找到通义千问平台API配置选项,将决策层大模型下的tongyi_app_id参数更换成自己的应用ID  ### 6.2 使用其他供应商的决策层模型 在上一步配置决策层模型中,默认使用的是通义千问VL-Max-2025-04-08模型,也可以选择来自其他供应商的模型,不同供应商的可用模型会随百炼模型官方运营情况变化。 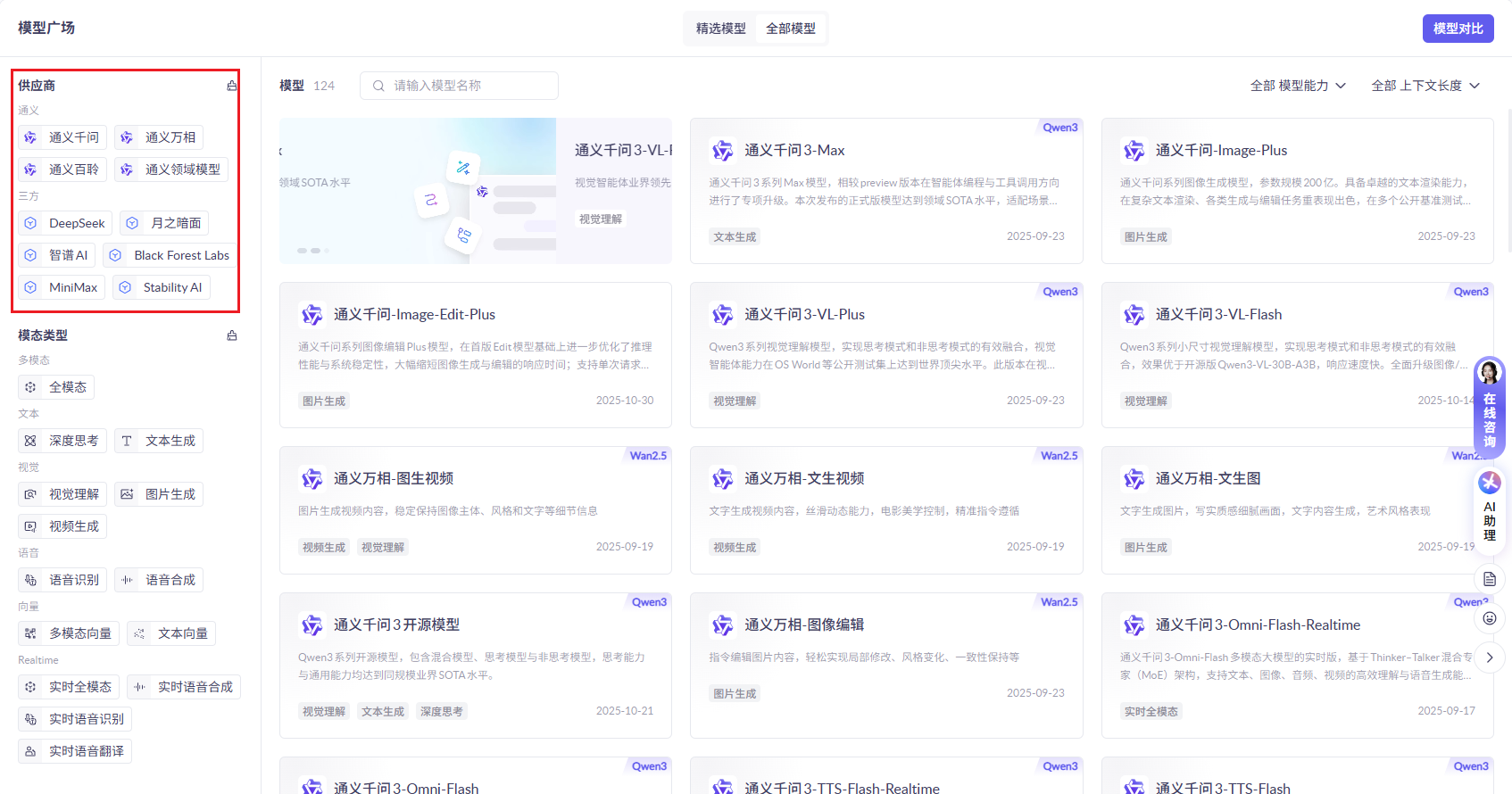 ### 6.3 执行层大模型配置 注意:执行层模型必须要用视觉多模态模型,不同模型在指令遵循能力上有所差异,尽量选择新的模型进行测试,部分模型如果回复不符合要求,会导致后续解析出现错误,机器人无法正确执行动作。 打开large_model_interface.yaml配置文件,找到执行层大模型配置选项:  在multimodel参数中可以修改执行层的大模型,填写模型的**code名称**即可,注意需要使用多模态视觉模型 可用模型列表参考百炼平台(通义千问平台)—模型广场—图片理解模型:[视觉模型列表](https://bailian.console.aliyun.com/?spm=5176.29597918.J_SEsSjsNv72yRuRFS2VknO.2.55997b08jKDchF&tab=model#/model-market?capabilities=%5B%22IU%22%5D&z_type_=%7B%22capabilities%22%3A%22array%22%7D) 在此页面点击模型,可以查看模型的**code名称**和**剩余额度** 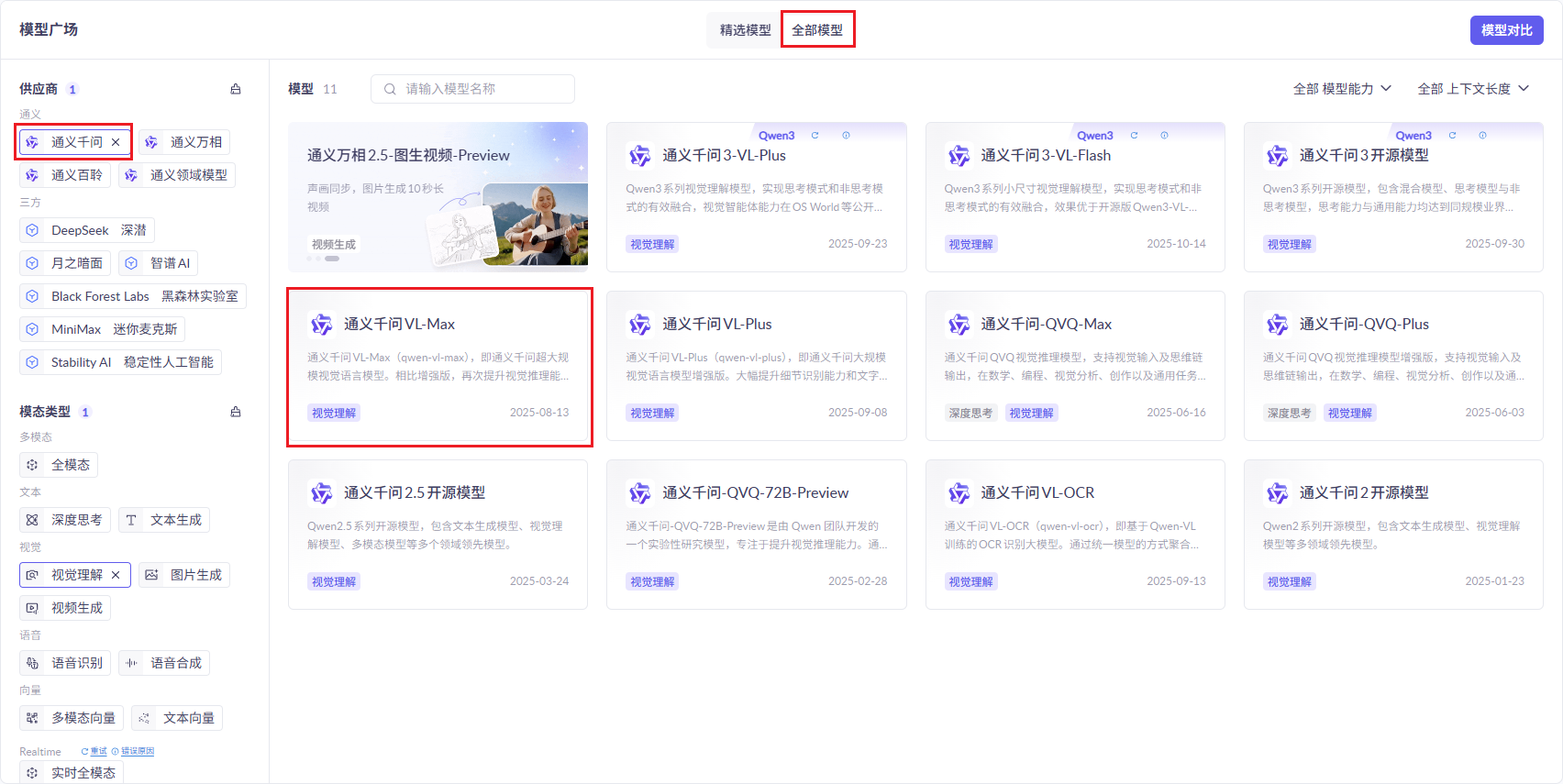 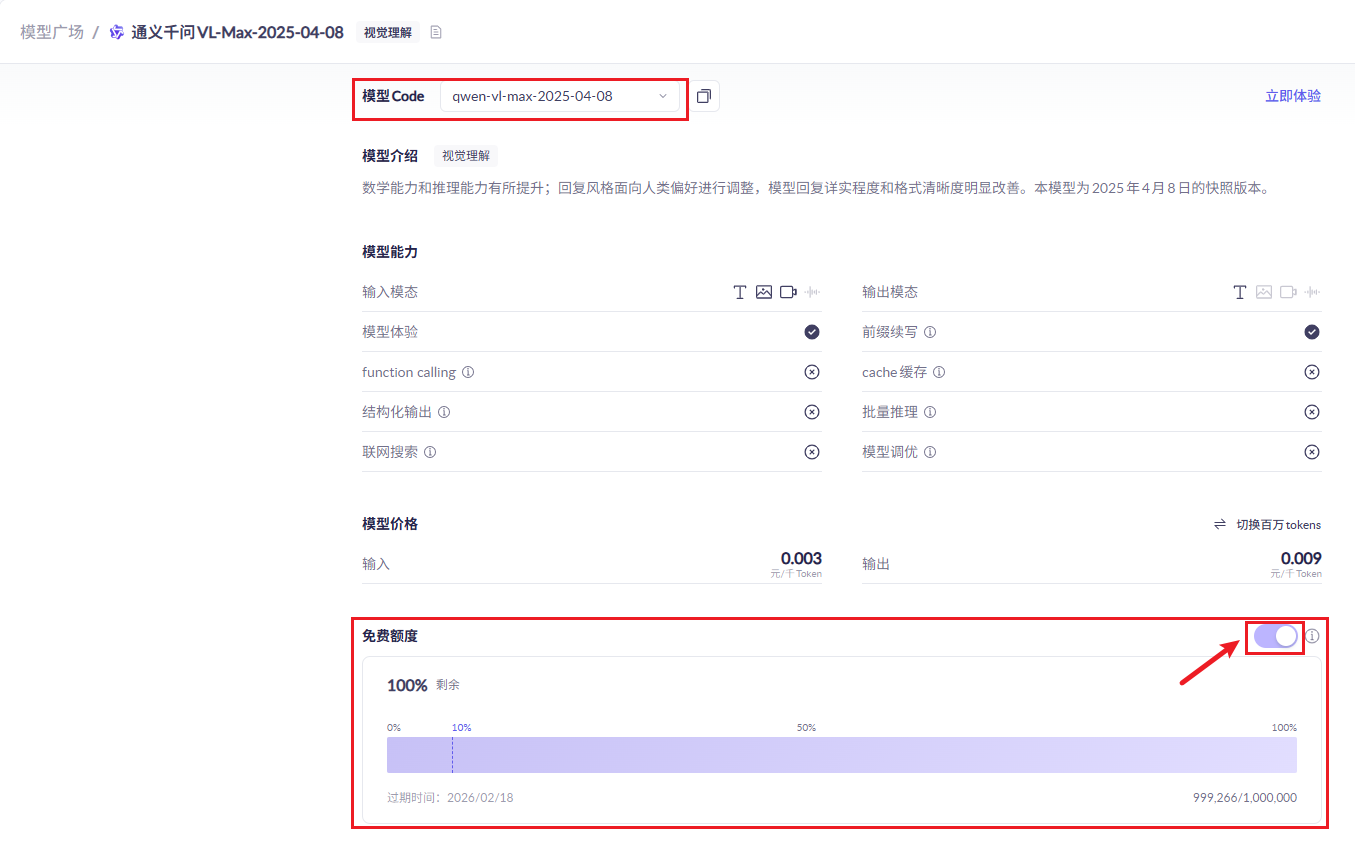 >i **信息提示** > > 注:如果其中一个模型的免费额度用完了,并且欠费,则其他所有模型的免费额度均无法使用,会出现大模型连接失败的错误。因此建议将“免费额度用完即停”开关打开,避免出现无法使用的情况。 可以页面右上角点击”费用“,查询是否欠费。 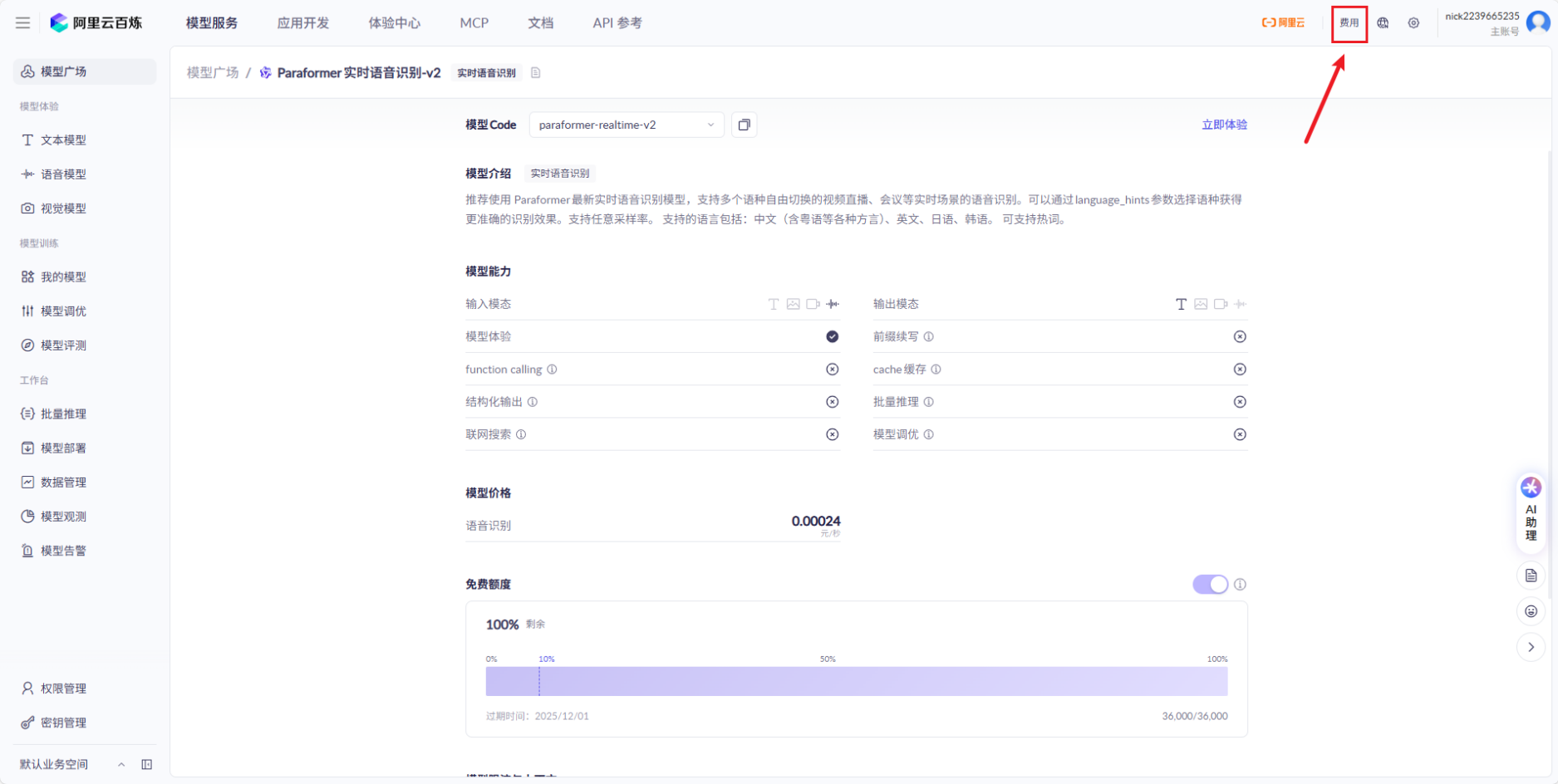  欠费账户如下所示: 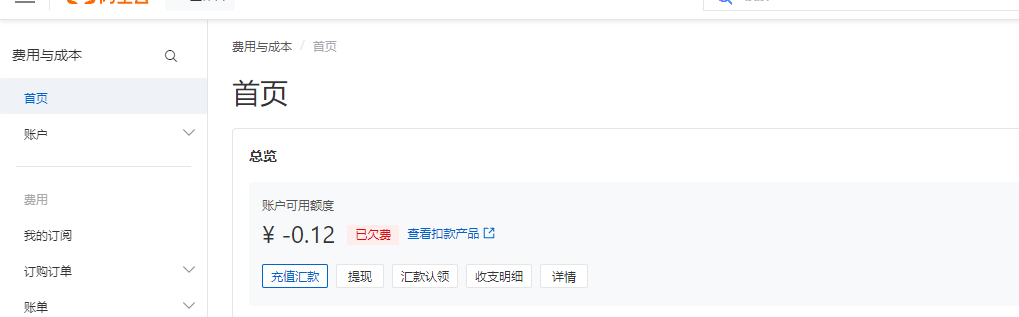 ### 6.4 保存生效配置 每次修改完大模型的配置参数后,都需要重新编译功能包才能生效配置,方法如下: 在车机终端切换到yahboomcar_ros2_ws/yahboomcar_ws/工作空间下:重新编译largemodel功能包生效配置 `colcon build --packages-select largemodel` 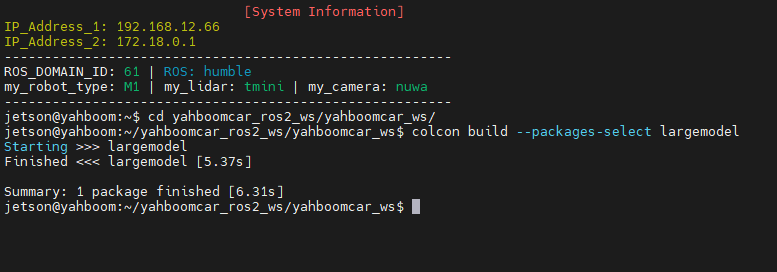
admin
2025年11月29日 13:39
20
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期
AI