ROS2自动驾驶
yolo5自动驾驶
1、重要!更换U盘的操作指引
2、关闭开机自启动大程序
3、Linux基础
4、YoloV5训练集
5、自动驾驶基础调试(代码解析)
6、自动驾驶特调
7、自动驾驶原理
8、PID算法理论
9、阿克曼运动学分析理论
10、建立运动学模型
常用命令
!重要!首次使用
一、原理分析
麦克纳姆轮运动学分析
二、AI大模型
3、AI大模型类型和原理
4、RAG检索增强和模型训练样本
5、具身智能机器人系统架构
6、具身智能玩法核心源码解读
7、配置AI大模型
8、配置API-KEY
三、深度相机
2、颜色标定
10、深度相机的基础使用
11、深度相机伪彩色图像
12、深度相机测距
13、深度相机色块体积测算
14、深度相机颜色跟随
15、深度相机人脸跟随
16、深度相机KCF物体跟随
17、深度相机Mediapipe手势跟随
18、深度相机视觉循迹自动驾驶
19、深度相机边缘检测
四、多模态视觉理解
20、多模态语义理解、指令遵循
21、多模态视觉理解
22、多模态视觉理解+自动追踪
23、多模态视觉理解+视觉跟随
24、多模态视觉理解+视觉巡线
25、多模态视觉理解+深度相机距离问答
26、多模态视觉理解+SLAM导航
27、多模态视觉理解+SLAM导航+视觉巡线
28、意图揣测+多模态视觉理解+SLAM导航+视觉功能
五、雷达
8、雷达基础使用
思岚系列雷达
六、建立地图
9、Gmapping建图
cartographer快速重定位导航
RTAB-Map导航
RTAB-Map建图
slam-toolbox建图
cartographer建图
Navigation2多点导航避障
Navigation2单点导航避障
手机APP建图与导航
七、新机器人自动驾驶与调整
多模态视觉理解+SLAM导航
新机器人自动驾驶
场地摆放及注意事项
启动测试
识别调试
无人驾驶的车道保持
无人驾驶路标检测
无人驾驶红绿灯识别
无人驾驶之定点停车
无人驾驶转向决策
无人驾驶之喇叭鸣笛
无人驾驶减速慢行
无人驾驶限速行驶
无人驾驶自主泊车
无人驾驶综合应用
无人驾驶融合AI大模型应用
八、路网规划
路网规划导航简介
构建位姿地图
路网标注
路网规划结合沙盘地图案例
路径重规划
九、模型训练
1、数据采集
2、数据集标注
3、YOLOv11模型训练
4、模型格式转换
十、YOLOV11开发
多机通讯配置
汝城县职业中等专业学校知识库-信息中心朱老师编辑
-
+
首页
二、AI大模型
5、具身智能机器人系统架构
5、具身智能机器人系统架构
## 名词解释:具身智能是人工智能与机器人学交叉的前沿领域,强调智能体通过身体与环境的动态交互实现自主学习和进化,其核心在于将感知、行动与认知深度融合。具身智能领域蕴含着巨大的市场潜力和发展机遇,随着技术的不断成熟、应用的不断拓展,具身智能产品将在智能制造、智能家居、智慧医疗、智能服务等多个领域发挥重要作用。在技术方面要通过优化算法、提高硬件性能等方式,采用加密技术、数据脱敏等手段保护用户数据安全和隐私。此外也要制定具身智能技术伦理和道德准则加强对具身智能技术的监管和评估确保其行为符合人类道德和价值观。 具身智能的基本原理之一是身体和智能相互依存 。智能体的身体形态不仅限制了其在环境中的行动能力,也在一定程度上塑造了智能体的认知方式。这一观点认为,智能并非仅仅存在于“头脑”中,而是通过智能体的身体及其在环境中的互动表现出来的。身体在环境中的感知、反馈和适应使智能体能够更灵活地应对复杂任务,因此,身体的形态和运动方式直接影响智能体的认知和决策过程。 ## 1.课程内容 1.讲解AI具身智能机器人的大模型推理架构 2.对系统中的基础概念进行讲解,为后续课程实操做好铺垫 ## 2.系统组成 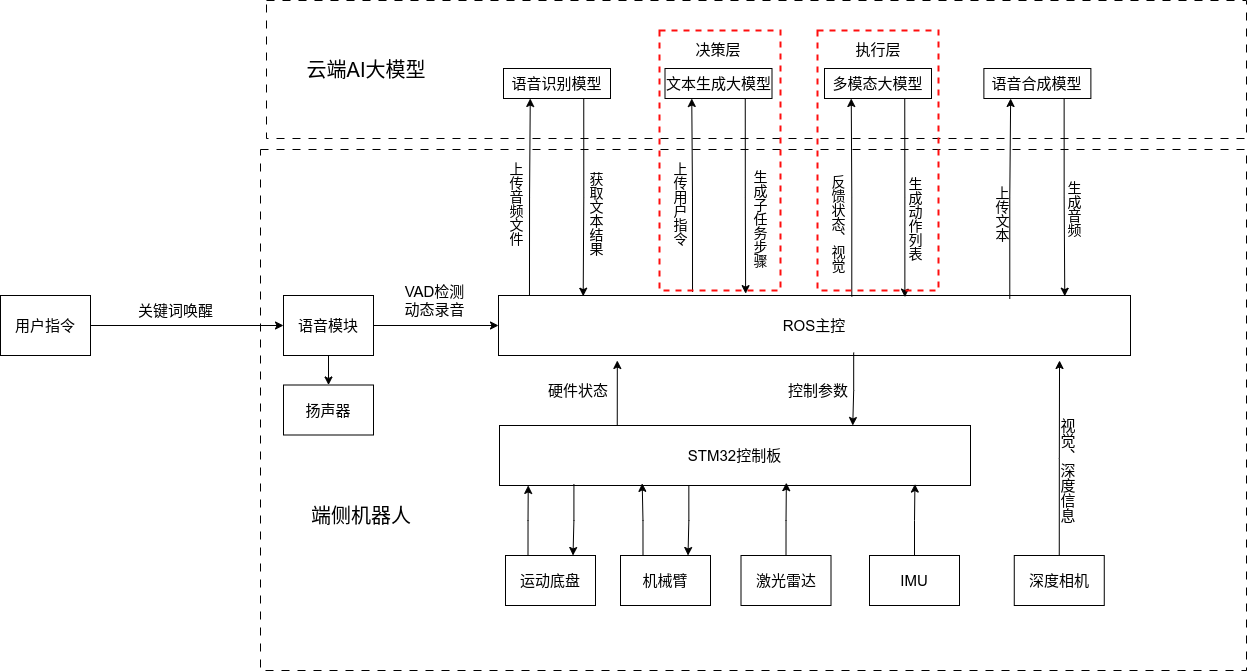 ## 3. AI大模型推理架构图 机器人在程序设计上采用**双模型推理**、**动态反馈推理**的设计,提高了机器人在面对长流程复杂任务时的处理能力,相比单模型架构具备更强的系统鲁棒性。这里有几个关键的概念:决策层大模型、执行层大模型、任务周期、对话历史,在下文中将进行逐个讲解。 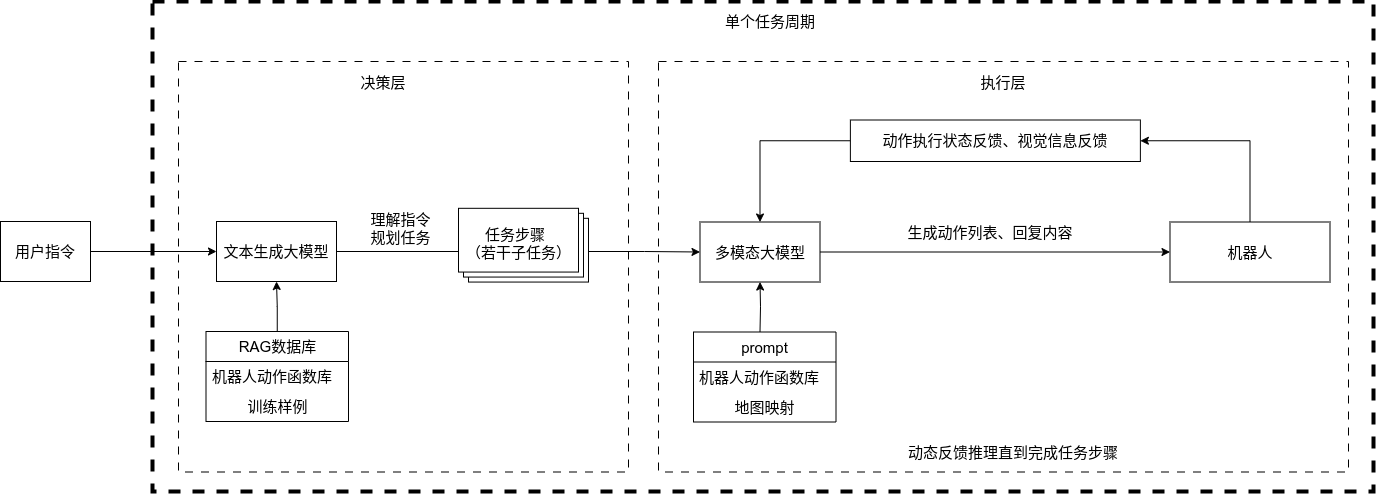 ## 4. 大模型推理架构讲解 ### 4.1 双模型架构原理 1、机器人的大模型控制系统基于文本生成大模型和多模态大模型设计,其中文本生成大模型作为**决策层**,其作用是作为上层的任务规划器,对复杂、抽象的人类指令进行任务分解 2、多模态大模型作为执行层,其作用是接收**决策层**生成的任务步骤以及用户的**临时指令**(一般是一些要求机器人结束任务、休息的简单指令)、监督机器人执行任务的进度并实时进行调整执行动作,生成机器人能解析的动作函数列表以及对用户的回复 3、其中,动作函数列表中是已编写好的基础动作函数,能够直接输出控制机器人运动的参数。 ### 4.2 双模型推理架构的优势 #### 4.2.1 决策逻辑与动作控制解耦 1、多模态大模型在对自然语言语义理解、逻辑推理的能力上差于文本生成大模型,并且在执行复杂任务时容易出现模态干扰,因此在系统设计上将决策逻辑与动作控制进行解耦。 2、文本生成大模型专注于语义理解与任务规划(如解析 “你能帮我取房间A中的蓝色方块吗?” 拆分任务步骤为 “记录当前的位置→导航至房间A→获取当前机器人视角图像→定位蓝色方块坐标→抓取蓝色方块→返回出发时的位置→放下蓝色方块 ),避免传统单模型在语义解析时需同时处理动作细节的复杂性。 3、多模态大模型负责动作生成与环境交互(如获取视觉图像定位出物体坐标,输出动作函数和参数),减少单模型因任务复杂导致的动作逻辑混乱,偏差较大的情况。 #### 4.2.2 降低模型训练样本复杂度 使用单一模型方式推理时,多模态大模型需同时进行 “自然语言理解 + 环境感知 + 流程拆解+动作函数输出”,易出现**模态干扰**(语言歧义或指令过长导致理解错误)。双模型通过分阶段处理,使决策层专注语言空间映射,执行层专注视觉 - 运动空间映射。 #### 4.2.3 灵活扩展 决策层和执行层大模型可在阿里百炼大模型平台(有时也称通义千问平台)选用多种大模型灵活搭配,通过自定义的训练样本和RAG知识库,可以使模型适应不同场景下的任务,极大增加了AI具身智能机器人在不同场景下的泛化能力。 ### 4.3决策层大模型 #### 4.3.1 决策层模型作用 1、机器人的决策层大模型默认使用学校的大模型。 2、决策层大模型主要负责任务规划,它可以理解复杂的人类指令并将其分解为具体的任务步骤。例如,当接收到指令“你能帮我去厨房拿瓶矿泉水吗?”,大语言模型会将其拆解为几个任务,如下图所示。 3、每个任务步骤对应机器人能完成的最小动作,再由执行层大模型通过调用这个机器人的动作函数库中的API函数来实现具体的机器人运动。 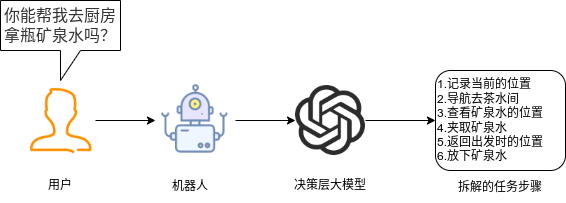 #### 4.3.2 机器人动作函数库(简化)——NUWA深度相机 机器人动作库中规定了所有机器人能够实际执行的最小动作,决策层模型在规划任务步骤时,会从中选取合适的动作进行排列组合 基础动作类 左转x度 #### 右转x度 #### 前进x米 #### 后退x米 #### 左移x米 #### 右移x米 导航移动类 **导航到x点** 相近语义:去x点、到x点、请你去x点。 **返回初始位置** 相近语义:回到初始位置、返回起点。 **记录当前位置** 深度相机类 **开始人脸跟随** 相近语义:开始xx跟随。 **开始巡线自动驾驶** 相近语义:开机xx巡线驾驶。 获取图像类 **获取当前视角图像** 说明:调用后机器人上传一张640×480像素的俯视图像,用于物体定位。 其他函数 **结束当前任务周期** 说明:清空上下文,结束任务(如用户指令“退下”“休息”)。 **等待一段时间** 说明:暂停x秒(x为等待时间,单位:秒)。 ### 4.4 执行层大模型 1、机器人的执行层大模型默认使用学校的大模型。 2、执行层大模型主要负责生成控制机器人行动的动作列表以及对用户的回复,在机器人执行动作列表过程中,不断接收来自机器人执行动作结果的反馈(成功/失败)、视觉图像,并根据动作执行的状态成功与否推测下个应该执行的动作 3、执行层大模型相当于一个监督者,不断监督机器人执行任务步骤的进度,并根据机器人执行动作后的结果反馈、环境信息来思考判断接下来该执行的动作,直到成功完成任务或因特殊情况提前结束任务。  #### 4.4.1 任务周期 1、在一个新的任务周期中,用户的指令会先经过决策层大模型,再经过执行层大模型,如果执行层大模型判定机器人完成了全部任务步骤时,会进入等待状态,此时用户后续的指令会直接交给执行层大模型。 2、例如:当用户要求结束当前任务、让机器人退下休息时,机器人会重置对话历史和机械臂状态,开启新的任务周期,此时用户的指令会从决策层大模型开始执行。以下是等待状态示意: 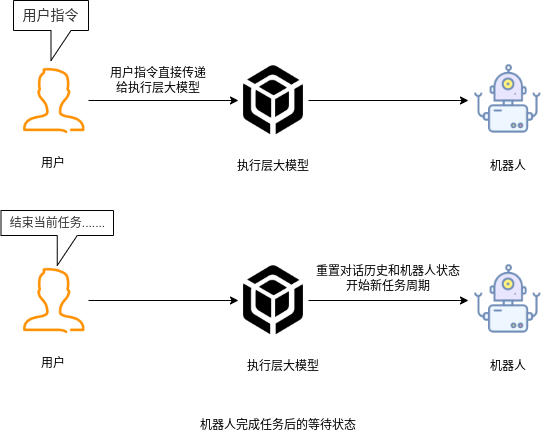 #### 4.4.2 历史上下文 机器人会在本地的程序中自行维护一个对话历史上下文,对话历史上下文中包含了用户的指令、决策层模型生成的任务步骤、执行层模型生成的动作列表、机器人反馈的状态信息,机器人每次请求执行层大模型时,发送的都是完整的对话历史,因此执行层大模型才能知道机器人执行任务的进度、执行层大模型会结合对话历史上下文,推测出接下来应该执行的动作,总结来说,**执行层大模型会根据过去的状态总和来推导出未来下一步的动作**。 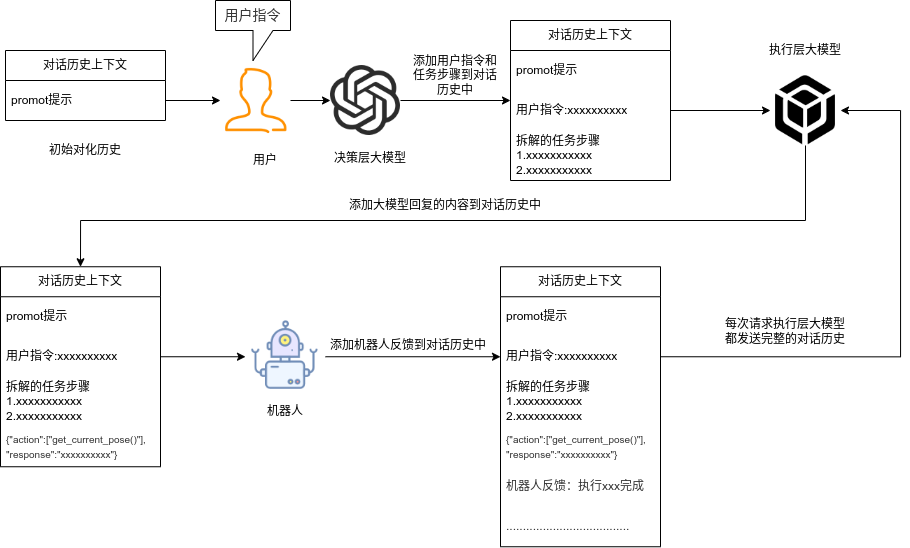 正常情况下,执行层大模型会根据对话历史判定完成任务的进度,当判定机器人完成了全部任务步骤时,会进入**等待状态**,等待用户的临时指令,临时指令不会再经过决策层大模型,而是直接传递给执行层大模型,有三种情况会导致机器人清空对话上下文历史、结束当前任务周期,开启新的任务周期。 **情况1**:用户主动要求结束任务周期,等待状态下,用户提出类似:"你先休息吧"、"你退下吧"等不再需要机器人的话时,执行层大模型会调用finish_dialogue()函数结束当前任务周期让机器人重置对话历史,开启新的任务周期,下述情况同理。 **情况2**:机器人在执行某个动作时连续失败两次,如果某个动作时失败后,执行层大模型会控制机器人最多重试一次,如果再次失败,则执行层大模型会控制机器人提前结束任务周期,开启新的任务周期。 **情况3**:机器人遇到不可能完成的任务时,例如当用户要求机器人去到一个未在"地图映射"中提到过的地点时,机器人会要求提前结束任务周期并告知用户无法完成这个任务。 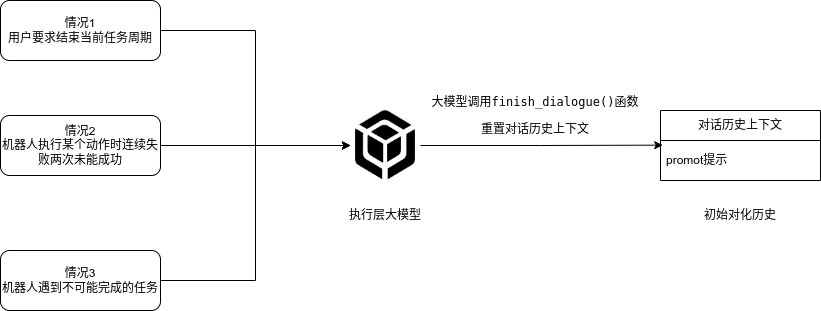 ### 4.4.3 地图映射 机器人进行导航时使用的是栅格地图,如果需要机器人理解真实世界中的位置区域,则需要让栅格地图和现实环境区域之间建立一个映射关系,这个关系成为地图映射。假设,我们使用机器人在一个工厂环境中使用SLAM建图生成一张栅格地图,在现实工厂中有若干个人为划分的区域,如下图所示 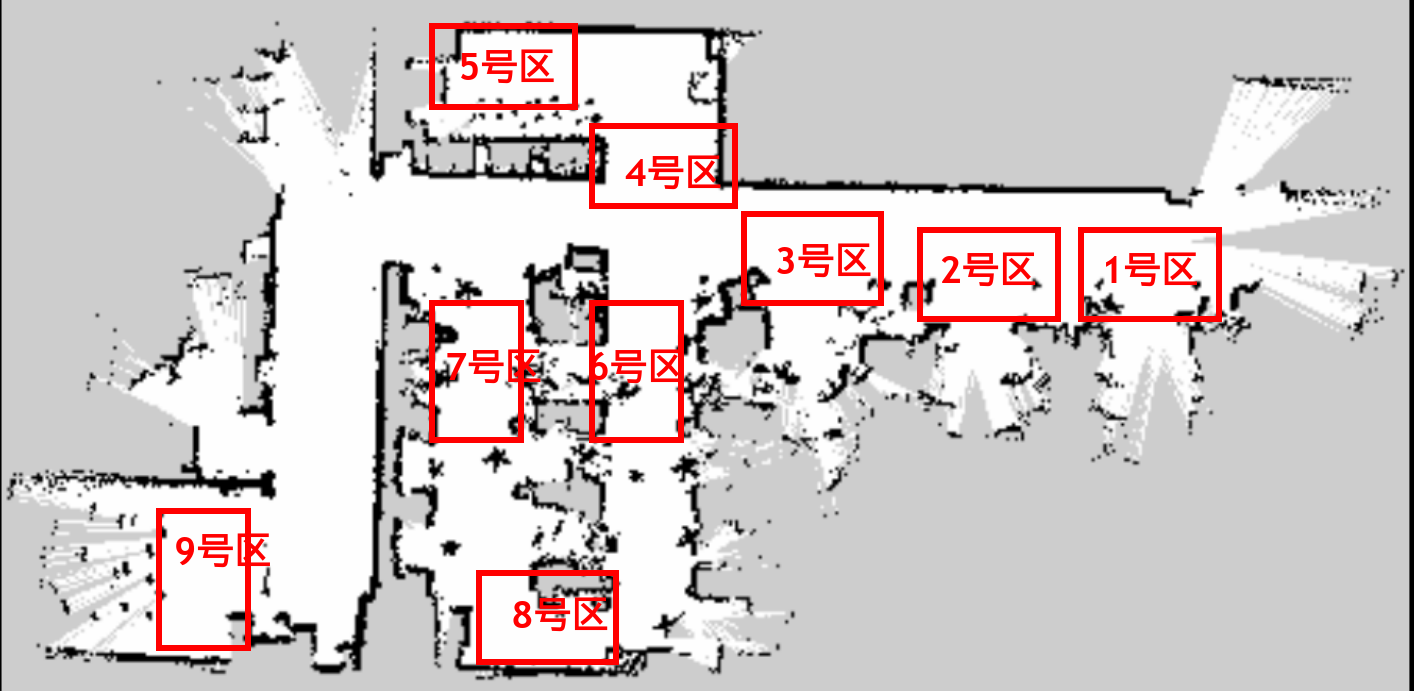 我们将这些现实环境中的区域与字母符号之间建立一一对应的关系 A:“1号区”、B:“2号区”、C:“3号区”、D:“4号区”、E:“5号区”、F:“6号区”、G:“7号区”、H:“8号区”、I : “9号区” 然后在yaml文件中对字母符号写入地图坐标,例如: ``` A: name: '1号区' position: x: 4.4034953117370605 y: 0.4879316985607147 orientation: x: 0.0 y: 0.0 z: 0.701498621044694 w: 0.7126708108744126 ``` 当我们要求机器人去往某个实际区域时,只需让大模型转换成对应的字母符号,这样机器人就可以理解现实环境中区域地点 ### 4.4.4 机器人动作函数库 机器人动作函数库中的API函数是大模型控制机器人与现实世界中进行交互的桥梁,这些API函数规定了实体机器人在物理世界中能完成的最小动作,API函数的原理是通过ROS2系统控制实体机器人的底层硬件来完成各种功能。 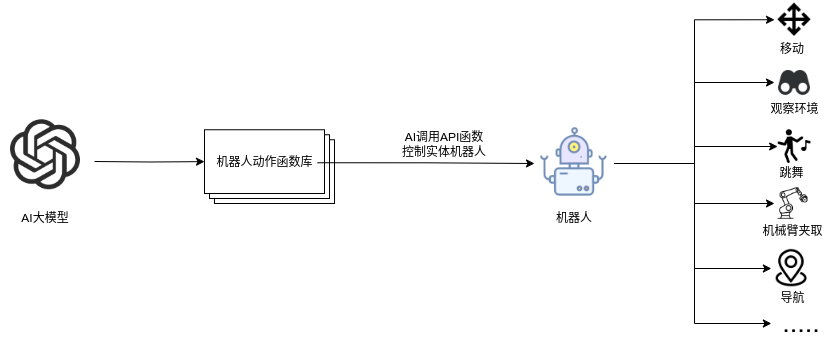 所有动作函数和对应功能如下表所示: 共用函数 | 函数名 | 参数 | 实现功能 | 调用指令 | |-----------------------------------------------------|-----------------------------------------------------------------|-----------------------------|-------------| | move_left(x, angular_speed) | x:转动角度、angular_speed:转动角速度 | 左转x度/逆时针旋转一圈 | 左转x度 | | move_right(x, angular_speed) | x:转动角度、angular_speed:转动角速度 | 右转x度/顺时针旋转一圈 | 右转x度 | | set_cmdvel(linear_x, linear_y, angular_z, duration) | linear_x:x轴线速度、linear_y:y轴线速度、angular_z:z轴角速度、duration:话题发布持续时间 | 通过设置线速度和角速度控制机器人底盘移动 | 前进、后退 | | navigation(x) | x:目标点在地图映射中对应的符号 | 控制机器人导航至目标点 | 导航去某个地点 | | navigation(zero) | zero:已经记录的坐标点 | 导航回到上一个记录的坐标点 | 回到原点、出发时的位置 | | get_current_pose() | - | 记录当前在全局地图中的坐标到zero参数中 | 记住现在的位置 | | seewhat() | - | 拍摄一张机器人当前视角的图像并上传给执行层大模型 | 观察环境 | | wait(x) | x:时间,单位:秒 | 等待一段时间,不执行任何操作 | 等待x秒 | | finishtask() | - | 机器人完成任务后自动调用,用于停止向执行层模型反馈状态 | - | | finish_dialogue() | - | 机器人结束本轮对话,开启新一周期 | - | | drift() | - | 小车漂移 | - | | dance() | - | 小车跳舞 | - | 我们机器人专有的函数 | 函数名 | 参数 | 实现功能 | 调用指令 | |-------------------------|-------------------------------------------------|---------------|------------------| | face_follow() | - | 人脸跟随功能 | 开始进行人脸跟随 | | qrFollow() | - | 二维码跟随功能 | 开始进行二维码跟随 | | apriltagFollow() | - | 机器码跟随功能 | 开始进行机器码跟随 | | colcor_follow(color) | color取值:'red'、'green'、'blue'、'yellow' | 颜色跟随功能 | 开始黄色跟随 | | KCF_follow(x1,y1,x2,y2) | 分辨率640×480像素,(x1,y1)为物体外边框左上角坐标,(x2,y2)为右下角坐标 | 物体跟随功能 | 开始跟随我手中的物体 | | gestureFollow() | - | 手势跟随功能 | 开始进行手势跟随 | | poseFollow () | - | 姿态跟随功能 | 开始进行姿态跟随 | | stop_follow() | - | 停止所有正在运行的跟随活动 | 停止跟随 | | follow_line(color) | 自动循迹指定颜色, color取值:'red'、'green'、'blue'、'yellow' | 颜色巡线功能 | 开始巡绿线 | | get_dist(x,y) | 获取xx物体的中心坐标(x,y)距离信息 | 获取指定物体的距离 | 请告诉我你面前风扇和你之间的距离 | ### 5. 语音模型在系统中应用 #### 5.1 语音识别 由于决策层和执行层大模型分别是文本生成模型和视觉多模态模型,无法直接接收用户的语音信息,所以需要使用语音识别大模型将用户语音指令转换成对应的文字,再交给AI大模型。 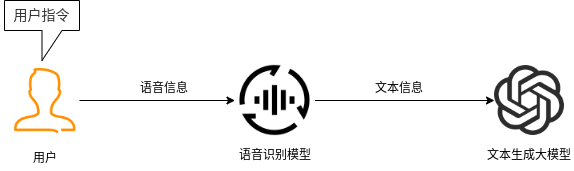 #### 5.2 VAD语音活动检测 VAD(语音活动检测) 能自动识别语音信号中语音段与非语音段(如静音、噪声)的技术。从音频流中定位语音的起始和结束位置,过滤掉无效背景声音。 在后续实操课程中,当用户使用唤醒词"你好小亚",唤醒机器人后,将进入VAD语音活动检测,系统会自动自动检测用户的说话时长,并将有效的声音片段保存WAV音频文件,然后将音频文件给语音识别模型转换成文字。 #### 5.3 语音合成 大模型对用户生成的文本回复通过语音合成模型转换成音频 ,再由硬件扬声器进行播放 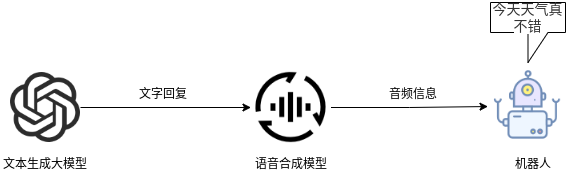
admin
2025年11月29日 13:03
38
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期
AI