ROS2自动驾驶
yolo5自动驾驶
1、重要!更换U盘的操作指引
2、关闭开机自启动大程序
3、Linux基础
4、YoloV5训练集
5、自动驾驶基础调试(代码解析)
6、自动驾驶特调
7、自动驾驶原理
8、PID算法理论
9、阿克曼运动学分析理论
10、建立运动学模型
常用命令
!重要!首次使用
一、原理分析
麦克纳姆轮运动学分析
二、AI大模型
3、AI大模型类型和原理
4、RAG检索增强和模型训练样本
5、具身智能机器人系统架构
6、具身智能玩法核心源码解读
7、配置AI大模型
8、配置API-KEY
三、深度相机
2、颜色标定
10、深度相机的基础使用
11、深度相机伪彩色图像
12、深度相机测距
13、深度相机色块体积测算
14、深度相机颜色跟随
15、深度相机人脸跟随
16、深度相机KCF物体跟随
17、深度相机Mediapipe手势跟随
18、深度相机视觉循迹自动驾驶
19、深度相机边缘检测
四、多模态视觉理解
20、多模态语义理解、指令遵循
21、多模态视觉理解
22、多模态视觉理解+自动追踪
23、多模态视觉理解+视觉跟随
24、多模态视觉理解+视觉巡线
25、多模态视觉理解+深度相机距离问答
26、多模态视觉理解+SLAM导航
27、多模态视觉理解+SLAM导航+视觉巡线
28、意图揣测+多模态视觉理解+SLAM导航+视觉功能
五、雷达
8、雷达基础使用
思岚系列雷达
六、建立地图
9、Gmapping建图
cartographer快速重定位导航
RTAB-Map导航
RTAB-Map建图
slam-toolbox建图
cartographer建图
Navigation2多点导航避障
Navigation2单点导航避障
手机APP建图与导航
七、新机器人自动驾驶与调整
多模态视觉理解+SLAM导航
新机器人自动驾驶
场地摆放及注意事项
启动测试
识别调试
无人驾驶的车道保持
无人驾驶路标检测
无人驾驶红绿灯识别
无人驾驶之定点停车
无人驾驶转向决策
无人驾驶之喇叭鸣笛
无人驾驶减速慢行
无人驾驶限速行驶
无人驾驶自主泊车
无人驾驶综合应用
无人驾驶融合AI大模型应用
八、路网规划
路网规划导航简介
构建位姿地图
路网标注
路网规划结合沙盘地图案例
路径重规划
九、模型训练
1、数据采集
2、数据集标注
3、YOLOv11模型训练
4、模型格式转换
十、YOLOV11开发
多机通讯配置
汝城县职业中等专业学校知识库-信息中心朱老师编辑
-
+
首页
yolo5自动驾驶
4、YoloV5训练集
4、YoloV5训练集
## 1、使用Yolov5训练交通标志 在前面的课程中有介绍到如何使用yolov5训练模型,本节课将通过实际操作来训练自己的模型,这里我们选择了训练交通标志,为了节省训练的时间,我们训练两种标志,多种标志的训练方法修改相对应的数值就可以了。 #### 注意: #### 由于Jetson Nano性能有限,无法完成训练模型。本次训练过程使用的是Jetson Orin NX 16G主板,也可以使用带独立显卡的电脑,训练过程仅供参考,需自备相关硬件设备。 ## 1.1、运行Get_garbageData.py生成训练集图片 我们先看看这个函数的主要部分 ``` # Generate images at random locations # 随机位置生成图片 def transparentOverlay(path): # Load image from file # 从文件加载图像 bgImg = cv.imread(path, -1) # reset image size # 重置图像大小 target = cv.resize(bgImg, (416, 416)) rows, cols, _ = target.shape # 背景图 rectangles = [] label = ' ' for i in range(0, 10): index = np.random.randint(0, 16) readimg = cv.imread('./image/' + str(index) + '.png') ``` 这里有两个关键信息点,一个是随机读取的数目大小,一个是读取图片的位置,分别对应的是 ``` index = np.random.randint(0, 16) readimg = cv.imread('./image/' + str(index) + '.png') ``` 由于我们只有两种交通标志,所以我们把16改成2,这里的数据是根据具体有多少种类型来修改的。在训练前,我们需要把这两种类型的图片,放在~/yolov5-5.0/data/garbage/image目录下,如下图所示  继续往下看看函数的主要内容 ``` def generateImage(img_total): rootdir = './texture' # List all directories and files in a folder # 列出文件夹下所有的目录与文件 list = os.listdir(rootdir) for i in range(0, img_total): index = np.random.randint(0, len(list)) txt_path = os.path.join(rootdir, list[index]) overlay, label = transparentOverlay(txt_path) cv.imwrite("./train/images/" + str(i) + ".jpg", overlay) with open("./train/labels/" + str(i) + ".txt", "w") as wf: wf.write(label) wf.flush() ``` 这里说明了,我们训练完成后的图片和标签的存放位置。训练结束后,会在这个目录下生成img_total张训练图片和训练标签,这里我们把img_total设置成100。 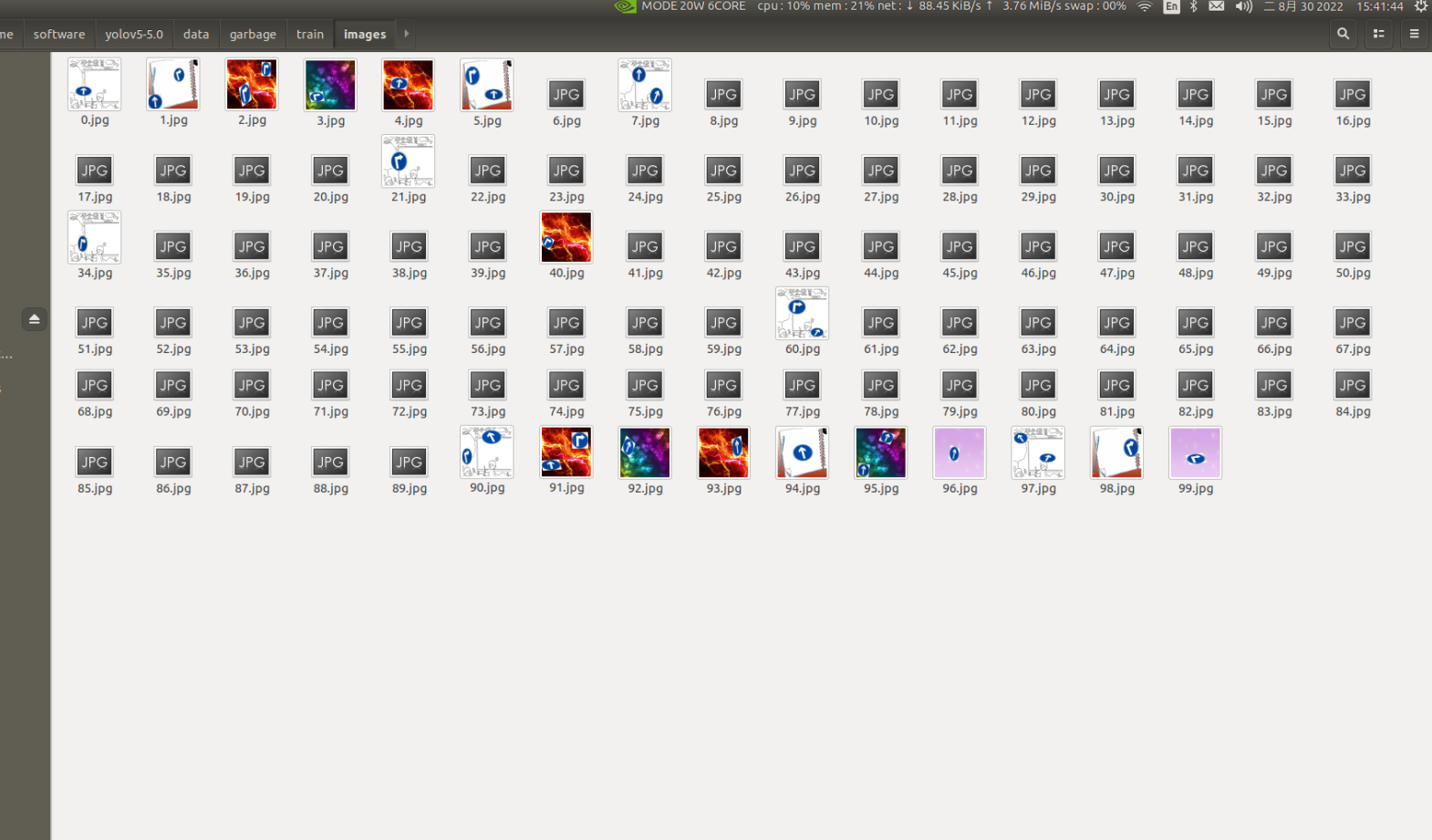 我们可以看看其中的一张训练图片,其实就是把图片进行一些处理,然后放在背景图片上,多种排列组合就形成了训练的图片了。  ### **1.2、修改yaml文件** 我们得到训练的图片后,一般来说就可以进行训练了,但是由于训练的图片比较大,所以我们需要通过一个文件去加载它。在~/software/yolov5-5.0目录下的train.py文件可知 ``` parser.add_argument('--data', type=str, default='data/garbage.yaml', help='data.yaml path') ``` 训练的时候,会加载这个yaml文件,这里边的内容就是训练好图片的路径以及相关标签的信息。 我们把这个yaml的内容修改成如下 ``` # train and val data train: /home/jetson/software/yolov5-5.0/data/garbage/train/images val: /home/jetson/software/yolov5-5.0/data/garbage/train/images # number of classes nc: 2 # class names names: ["Go_Straight","Trun_Right"] ``` train和val表示训练图片的位置,nc表示有多少种类型的图片,name表示这些图片的类型名字,需要与~/yolov5-5.0/data/garbage/image图片顺序保持一致。 ### 1.3、运行train.py训练模型 ``` cd ~/software/yolov5-5.0 python train.py ``` 成功运行截图如下图所示 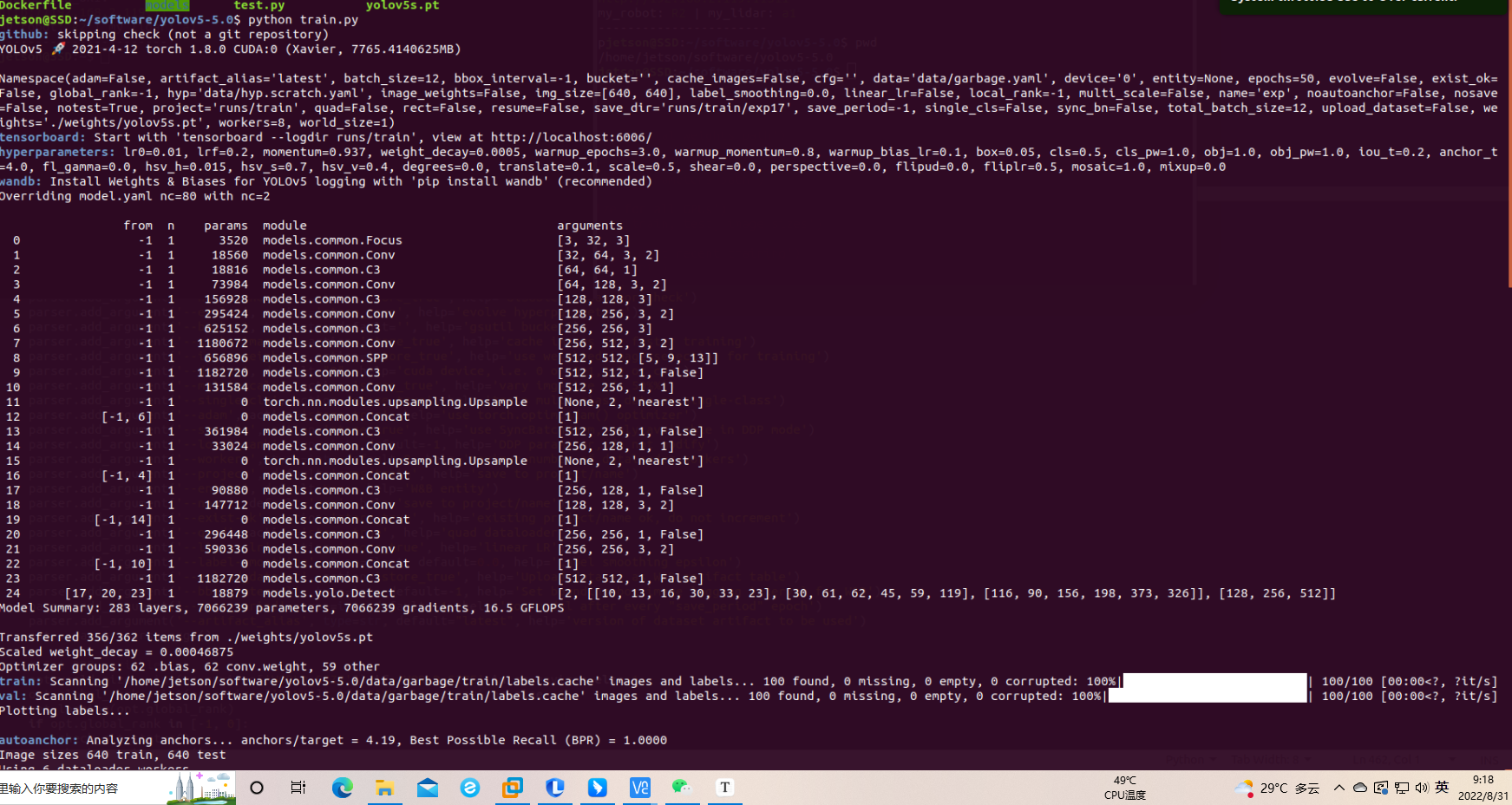 这里是训练了50次,也就是epoch数值为50。**如果是虚拟机来训练的话,则需要修改** ``` 把parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') 修改成,parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') ``` 训练完后会在终端打印出保存模型的路径,如下图所示  进到~/software/yolov5-5.0/train/runs/train/exp17查看里边的内容,里边的test_batch0_pred.jpg、test_batch1_pred.jpg和test_batch2_pred.jpg,是我们预测的图片  可以看出,识别准确率还是蛮高的。然后,我们把~/software/yolov5-5.0/train/runs/train/exp17/weights/best.pt放在~/software/yolov5-5.0目录下,然后修改detection_video.py里边的内容 ``` 把model_path = 'weights/yolov5s.pt'修改成, model_path = './best.pt ``` 运行detection_video.py,就可以使用我们刚才训练的模型,实时识别刚才训练地两个标志。如下图所示  ## 2、使用TensorRt加速识别标志 1、tensorrt部署流程 1.2、⽣成.wts⽂件 将上一节课生成best.pt复制到~/software/yolov5-5.0文件中,打开终端 ``` python3 gen_wts.py -w best.pt ``` 将生成的best.wts文件复制到tensorrtx_yolov5_jetson⽬录下,并在该⽬录下编译tensorrtx,终端输入 ``` mkdir build && cd build && cmake .. ``` 将yololayer.h⾥的CLASS_NUM修改成11,这里的11表示有多少种交通标志,我们训练了11种,所以是11。官⽅⽤的是coco数据集,默认是80。 执⾏makeFile。(每次修改为CLASS_NUM都要make⼀次) 终端输入 ``` make -j4 ``` ### 1.3、⽣成.engine⽂件 ⽣成.engine文件,终端输入 ``` sudo ./yolov5 -s ../best.wts yolov5s.engine s ``` 运行结束后,会在~/software/tensorrt_yolov5_jetson/build目录下生成libmyplugins.so 和yolov5s.engine ,把这两个文件复制到yahboomcar_yolov5功能包param/nano4G⽂件夹下(以nano4G为例,需要根据具体主控来修改)。 ### 1.4、编写yaml文件 在~/yahboomcar_ws/src/yahboomcar_yolov5/param目录下,新建一个yaml文件,命名为traffic.yaml,把以下内容复制到该文件里面 ``` PLUGIN_LIBRARY: libmyplugins.so engine_file_path: yolov5s.engine CONF_THRESH: 0.5 IOU_THRESHOLD: 0.4 categories: ["Go_straight","Turn_right","whistle","Sidewalk","Limiting_velocity","Shutdown","School_decelerate","Parking_lotB","Parking_lotA","Green_light","Red_light"] ``` ### 1.5、修改yolov5.py代码 修改~/yahboomcar_ws/src/yahboomcar_yolov5/scripts目录下的yolov5.py,把file_yaml的值修改成刚新建的traffic.yaml,如下边所示 ``` file_yaml = param_ + 'traffic.yaml' ``` ### 2、测试运行 以nano为例,终端输入 ``` roslaunch yahboomcar_yolov5 yolodetect.launch device:=nano4G ``` 如下图所示 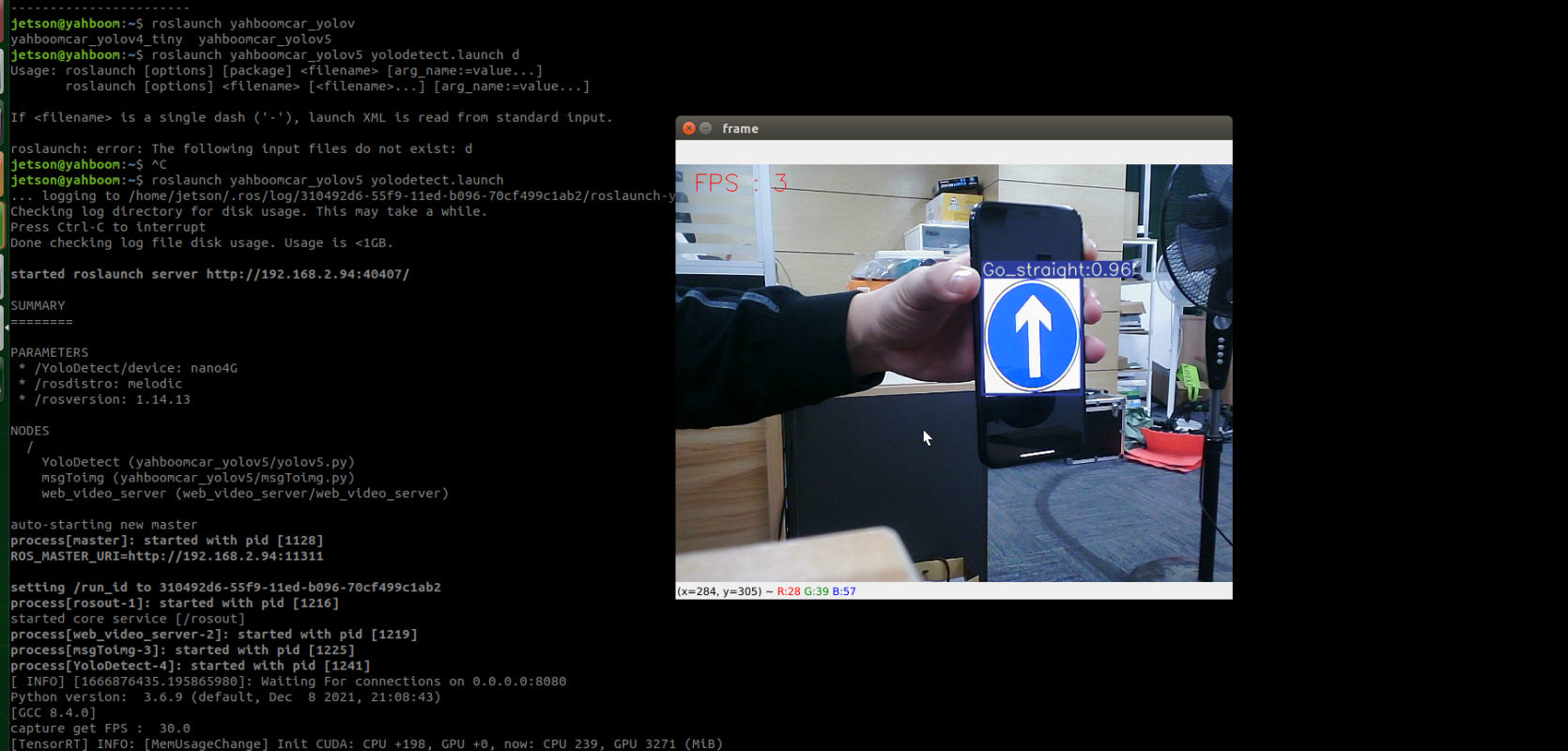 使用rostopic list查看话题,终端输入 ``` rostopic list ``` 如下图所示  我们可以看到有一个话题是/DetectMsg,这个就是识别出来的交通标志的具体信息,使用rostopic echo查看消息的具体信息,终端输入 ``` rostopic echo /DetectMsg ``` 如下图所示,红色框就是识别出来标志的具体信息,包含了frame_id也就是类别,分数,中心坐标等等,我们在后边程序中,只要是订阅了这个话题,就可以得到这些数据。 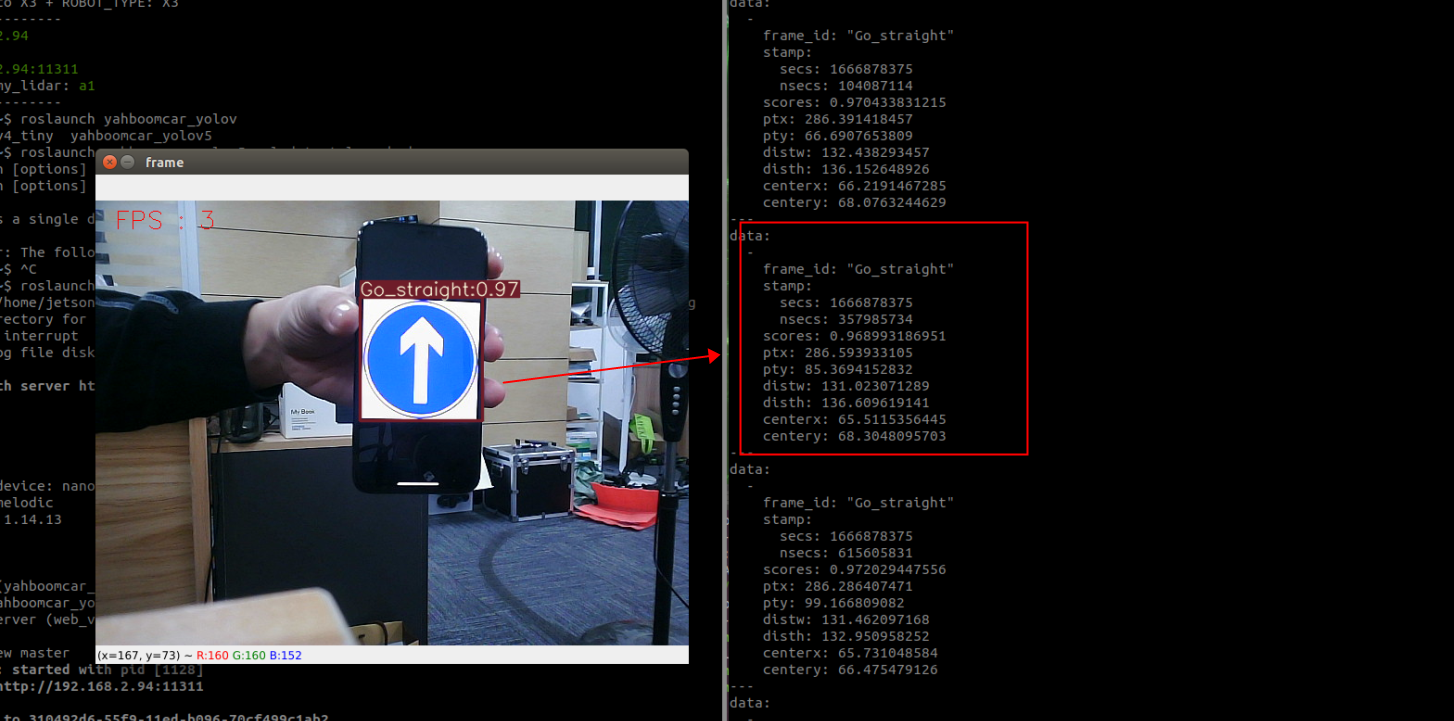 ## 路标指示功能说明 1、路标图片汇总  **1.前进 2.右转 3.鸣笛 4.人行道**  **5.限速 6.停止 7.学校 8.停车场B**  **9.停车场A 10.红灯关闭 11.红灯亮** **2、路标功能解释** **1.前进:小车前进** **2.右转:小车执行右转命令** **3.鸣笛:小车蜂鸣器响一声** **4.人行道:小车停止一段时间后,继续行驶** **5.限速:小车加速前进一段时间后,恢复原来速度行驶** **6.停止:小车停止** **7.学校:小车速度降低前进一段时间后,恢复原来速度行驶** **8.停车场B:小车倒车入库** **9.停车场A:小车倒车入库** **10.红灯关闭:小车前进** **11.红灯亮:小车停止** ## **采集数据** ### 一、安装cvui库 打开系统终端,输入以下命令安装cvui库。 ``` sudo pip3 install cvui ``` ### 二、代码分析 代码路径:Rosmaster/auto_drive/data_collection.py 1.初始化cvui库,cvui库基于opencv的图像化操作库,可显示多个窗口。 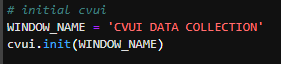 2.新建数据表,名称为road_following_A/B,用于存储数据图片信息。A/B为两个独立数据集,实际应用中只要用到A就可以。 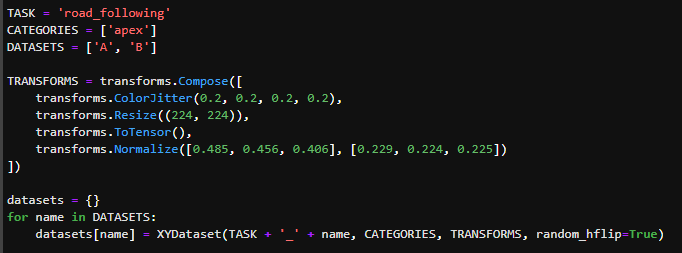 3.初始化摄像头,其中cv2.VideoCapture(0)中的0为摄像头/dev/video0的设备号,一般情况下,只接一个摄像头时为0,如果接入多个摄像头请根据ls /dev/video*查找获得摄像头编号。由于模型数据集需要的图片大小为224*224,所以需要修改图像大小为224*224。 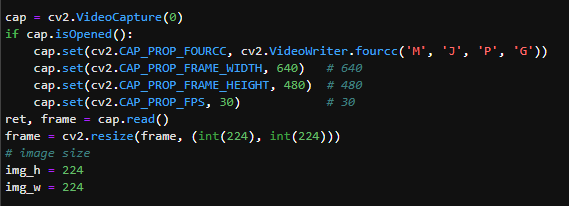 4.初始化数据表,并打印当前已有的数据图片的数量。 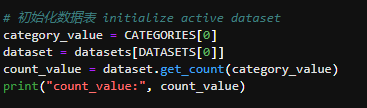 5.新建一个while循环读取摄像头的画面,并且显示在cvui的窗口上。然后监听鼠标的点击事件。 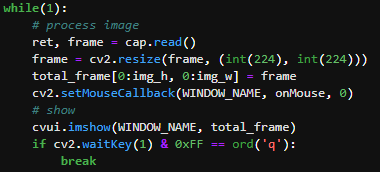 6.当检测到窗口有鼠标左键点击时,触发onMouse函数事件,若判断为摄像头区域内,则记录标记点的X Y坐标并将图像存起来。 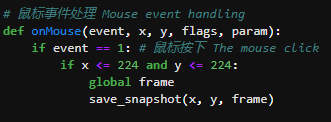 7.保存当前摄像头画面到本地和数据表,同时打印出当前的X Y值和数据图片的数量。 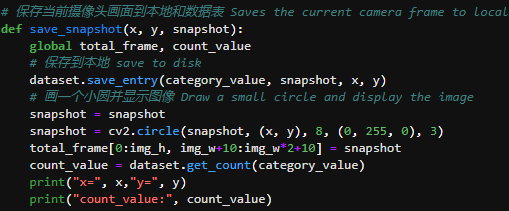 ### 三、开始采集数据 注意:由于opencv需要打开摄像头画面,所以需要在实际桌面上运行,可以用远程VNC桌面运行,但不可以远程SSH登录运行。运行命令前请先关闭其他打开摄像头的程序,否则会冲突报错。 运行以下命令 ``` cd ~/Rosmaster/auto_drive python3 data_collection.py ``` 如果使用的Jetson Xavier NX主控小车,由于内部多版本问题,需要使用python3.7来运行程序。 ``` cd ~/Rosmaster/auto_drive python3.7 data_collection.py ``` 此时会打印出当前已有图片数据集数量,并且显示一个窗口两个画面。左边的画面为摄像头的实时显示画面,右边的画面为鼠标点击后采集的图像画面,并增加了XY坐标绿色圆圈。每点击一次左边摄像头画面,count_value自动加1并保存图片和坐标信息。 注意:采集数据集时,需要将小车放到地图上,并且点击小车摄像头画面中的最优路径点,推动小车缓慢沿赛道前进,每前进一小步,就记录一次,记录完整个地图。可以多次记录数据集提高识别准确率。也可以另外打开一个终端运行手柄控制程序,用手柄控制小车移动。 ``` cd ~/Rosmaster/auto_drive/ python3 joystick_R2L.py ``` 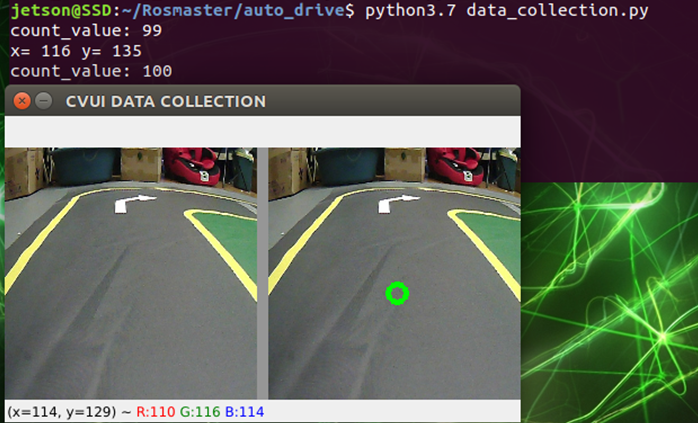 最后,按键盘q键退出采集数据功能。 ### 四、查看数据图片 图片生成路径: ``` Rosmaster/auto_drive/road_following_A/apex ``` 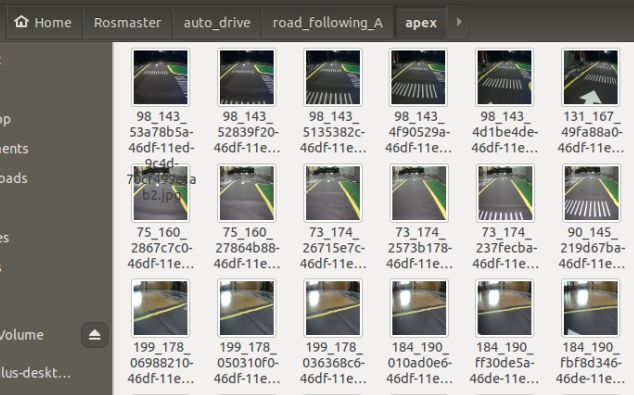 注意:如果发现有图片错误录入,需要取消时,请在此文件夹找到对应的图片删除掉。再重新运行data_collection.py程序即可。 ## 训练模型 一、开发环境 本次训练模型需要用到TensorFlow等相关工具,由于使用工具较多且部署复杂,ROSMASTER小车出厂镜像已经部署训练模型的开发环境,可以直接使用即可,不必重复搭建。 二、代码分析 具体代码请查看:Rosmaster/auto_drive/interactive_regression.ipynb 三、开始训练模式 用浏览器打开jupyter lab,找到interactive_regression.ipynb文件并打开,点击运行所有cell按钮,然后拉到最底下,等待控件显示。 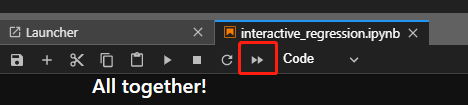 可以看到底部显示这部分内容,其中 dataset:表示数据库,一般选择A就可以; category:表示种类,只能选apex; count:表示数据集数量,即多少张图片; epochs:表示训练的次数,训练次数越多时间越久,模型就越准确(我一般输入30次); progress:表示训练进度; loss:表示目标函数值,正常情况随训次数的增加而缓慢下降,然后趋于稳定; train:开始训练; evaluate:评估数据集准确性; model path:模型名称,默认为road_following_model.pth,如果改动会影响调用模型; load model:加载模型,可以将已经训练好的模型加载; save model:保存模型,这个很重要,因为浏览器不会自动保存模型,请训练完成后一定要点击保存模型; state:stop表示关闭图像实时评估,live表示打开图像实时评估。 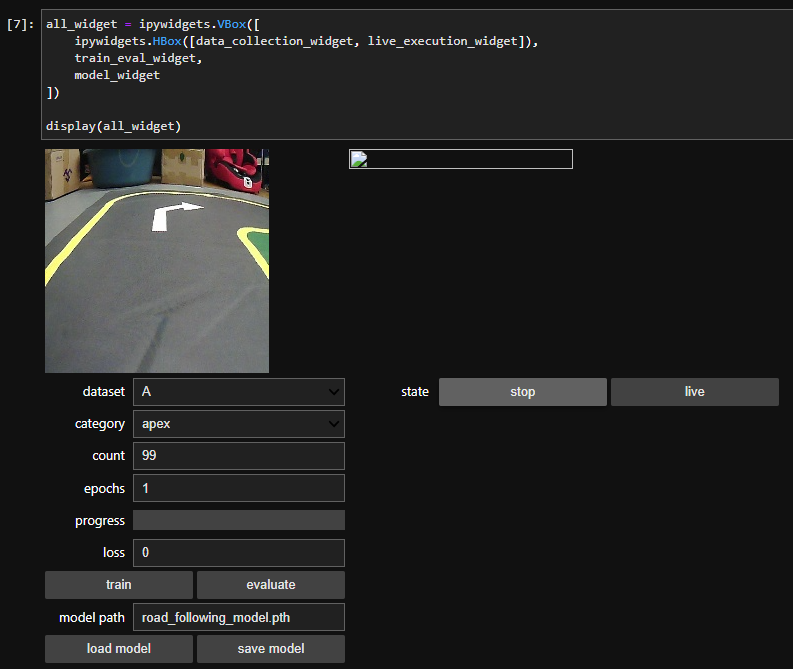 由于上一节采集数据完成,可以看到数据集的数量count为99,所以只需要修改epochs为30,然后点击train开始训练,等待训练完成后,点击save model保存模型即可。 ### 四、结束kernel 由于本次训练使用了摄像头,在结束训练后,需要将kernel关闭。在关闭kernel前,请先确认模型是否训练完成,并且保存起来,如果没有点击保存模型,将造成无法挽回的错误。 点击kernel管理栏,找到interactive_regression.ipynb并点击右边的X来结束。  ## 模型转化与应用 ### 一、开发环境 本次训练模型需要用到TensorFlow等相关工具,由于使用工具较多且部署复杂,ROSMASTER小车出厂镜像已经部署训练模型的开发环境,可以直接使用即可,不必重复搭建。 ### 二、代码分析 具体代码请查看:Rosmaster/auto_drive/road_following.ipynb 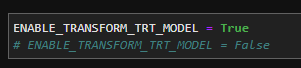 ENABLE_TRANSFORM_TRT_MODEL参数为转换模型的标志,如果为True则转化为trt模型,如果为Flase则不转化模型(认为已经有trt模型),直接加载trt模型。 ### 三、转换模式 用浏览器打开jupyter lab,找到road_following.ipynb文件并打开,点击运行所有cell按钮,,等待所有cell运行完成,蜂鸣器响一声‘滴’。  此时将小车放入赛道上,移动小车的位置,可以看到前轮舵机会有转动的变化。由于此时小车的速度为0,所以不会在赛道上跑,我们需要给小车传入速度让小车运动。 至于为什么不给小车直接设置速度,原因是启动模型转化需要一定时间,而且小车如果启动后就开启运动,有时候放的位置不是在赛道上,或者训练出来的模型有问题,小车会乱跑,所以建议用手柄控制小车速度的方式,方便调试。  ### 四、手柄控制小车 小车手柄控制代码路径:Rosmaster/auto_drive/joystick_R2L.py 将手柄接收器插入主控板的USB口,然后打开无线手柄的电源。 打开终端,运行以下命令打开手柄控制程序 ``` cd ~/Rosmaster/auto_drive/ python3 joystick_R2L.py ``` 此时按一下无线手柄的START键,可以听到蜂鸣器响则表示连接成功,松开START键蜂鸣器关闭。 无线手柄功能如下: | 手柄 | 效果 | |-----------|-------------| | 左摇杆上/下 | 小车前进、后退 | | 右摇杆左/右 | 小车前轮向左、向右 | | 方向键向前 | 小车前进(松开不停车) | | 方向键向后 | 小车后退(松开停车) | | L1键 | 速度调整为0.5 | | R1键 | 速度调整为0.3 | | L2/R2键 | 停车 | | "START"按键 | 控制蜂鸣器/结束休眠 | | X键 | 前轮向左微调 | | B键 | 前轮向右微调 | 手柄速度默认为0.3,可以按L1键或者R1键修改速度,不同速度值可能需要重新采集数据集并训练模型才能达到最优效果。然后按一下方向键的向前键,小车开始运动。如果小车跑出赛道,可以按L2或者R2停止,也可以按方向键向后退回来,松开方向键向后会自动停车。 五、结束kernel 由于本次训练使用了摄像头,程序运行完成后,需要将kernel关闭。 点击kernel管理栏,找到road_following.ipynb并点击右边的X来结束。 
admin
2025年11月26日 13:12
39
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期
AI